예전에 마소에 실었던 글을 조금 수정하였습니다.
C 거의 모든 소프트웨어의 인프라스트럭처가 되고 있는 강력한 언어이지만, 타입 안전성을 고려하지 않은 언어 디자인으로 각종 버그와 보안 사고의 원인이 되고 있다. 그 이후에 출연한 여러 고급 언어는 이런 타입 안전성 문제를 해결하였지만, 기존의 C 언어를 대체하는데 실패하였다. 싸이클론(Cyclone) 프로젝트의 목표는 타입 안전성을 제공하면서도, C 언어처럼 각종 인프라스트럭처 소프트웨어 작성에 사용될 수 있을 만큼의 자유도를 주는 언어를 만드는데 있다. 싸이클론 언어의 특성에 대해 살펴보자.
C 언어는 강력한 프로그래밍 언어이다. 운영체제 커널과 디바이스 드라이버, 파일 시스템, 웹 서버 등 오늘날 소프트웨어의 대부분은 C 언어로 작성되어 있다. 자바나 C#과 같은 고급 언어도 런타임과 컴파일러를 작성하는 데는 결국 C 언어가 사용된다. 인터넷의 혁명을 가능하게 만든 각종 네트워크 장비, 통신 설비 등에 들어가는 시스템 소프트웨어도 C 언어로 작성되어 있다.
하지만 C 언어는 강력한 동시에 위험하다. 뉴스를 오르내리는 각종 보안사고와 웜의 직접적인 원인은 잘못 작성된 소프트웨어에 있다. 하지만 기술적인 취약점의 대부분을 차지하는, 버퍼 오버플로우, 포맷 문자열 버그, 힙 오버플로우 등의 문제점은 결국 이 소프트웨어를 작성하는데 사용된 C 언어가 타입 안전성을 제공하지 않기 때문이다. 오늘날 소프트웨어의 작동이 멈추면 얼마나 끔찍한 일이 벌어질지 상상해보면, 그런 중요한 인프라스트럭처가 이처럼 취약한 C 언어로 만들어졌다는 사실이 놀라울 뿐이다.
그렇다면 대안은 무엇일까? 가장 쉽게 생각할 수 있는 방법은 타입 안전성을 제공하는 자바나 C#과 같은 언어로 기존의 소프트웨어를 새로 작성하는 것이다. 실제로 전통적으로 C 언어로 작성되던 일부 응용 소프트웨어는 이 방법으로 큰 성공을 거두었다. 실제로 고급 언어일수록 높은 생상성과 품질, 단축된 프로젝트 시간을 가져다줄 확률이 크기 때문이다.
하지만 정작 가장 중요한 시스템 소프트웨어는 어떨까? 자바로 작성된 방화벽, 스위치, 라우터는 어떤가? 반응 시간이 치명적으로 중요한 리얼 타임 시스템은 또 어떨까? 자바가 큰 성공을 거두긴 하였지만, 어디까지나 웹 어플리케이션과 임베디드용 응용 프로그램 등 특정 분야에 한정되어 있다. 아직도 저수준 제어와 직접적인 메모리 제어가 필요한 대부분의 중요 시스템은 C 언어로 작성된다.
싸이클론(Cyclone)는 이런 문제를 해결하고자 만들어진 언어이다. 싸이클론의 목표는 디바이스 드라이버나 커널을 만들 수 있을 만큼 강력한 코딩 파워를 가지면서도, 컴파일 타임에 많은 오류를 잡고 런타임에 발생하는 문제를 즉각 처리할 수 있는 자바 수준의 안전성을 가지는 언어를 만드는 것이다. 물론 C 언어로 작성된 기존 코드 베이스를 무시할 수 없으므로, C 언어로 작성된 프로그램을 최소한의 노력으로 싸이클론으로 포팅할 수 있게 한다. 따라서 싸이클론을 안전한 C 언어라고 부르기도 한다.
실제로 싸이클론 코드는 C 언어와 매우 유사하다. 싸이클론은 ANSI-C 표준에서 출발하여 임의의 타입으로의 캐스팅(casting) 같은 안전성을 해치는 기능을 버리고, 각종 타입 메커니즘을 추가한 언어이다. 싸이클론의 컴파일러는 프로그램 분석 방법을 이용해서 기존 C 언어 사용 방법 중에서 안전한 것들은 자동으로 싸이클론 타입을 유추해낸다. 최상의 경우 C 언어 코드를 그대로 컴파일할 수도 있다. 대부분의 경우 기존 C 코드에 약간의 어노테이션(일종의 프로그램 주석)을 붙여주는 정도만 해주면 된다.
C의 문제점과 싸이클론의 해법
C 언어에서 발생하는 가장 흔한 오류의 예로 버퍼 오버플로우가 있다. 배열의 크기보다 더 큰 인덱스로 배열을 읽으면, 자바에서는 ArrayOutOfBoundException이 나지만, C는 이에 대한 검사가 없기 때문에 그 주소 위치에 있는 임의의 메모리를 읽어오게 된다. 마찬가지 방법으로 배열을 끝을 넘어서는 메모리에 임의의 값을 쓸 수도 있는데, 그 값이 스택상의 리턴 주소일 경우 임의의 코드로 점프시킬 수도 있다. 이것이 C 언어에 대한 가장 흔한 공격 방법 중 하나인 버퍼 오버플로우 공격이다.
반대로 자바는 버퍼 오버플로우 공격이 불가능하다. 배열마다 배열의 길이를 저장하고 있고, 배열의 원소에 접근하기 전에 인덱스가 배열의 크기보다 작은지 런타임에 항상 검사를 수행하기 때문이다. 이런 검사를 통해 인덱스가 잘못 되었으면 ArrayOutOfBoundException을 던지는 것이다. 물론 C 언어에도 이와 유사한 방법을 사용할 수 있다. 하지만 C 언어는 배열뿐만 아니라 포인터와 포인터 연산이 존재하기 때문에 문제를 복잡해진다.
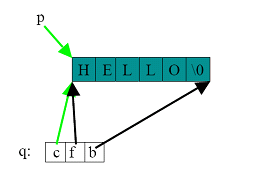
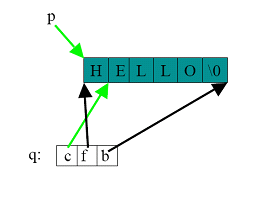
포인터 x는 배열의 처음, 중간, 끝 어느 위치든 가리킬 수 있다. x++이나 x--를 사용하면 메모리의 위치를 바꿀 수도 있다. 즉 현재 x가 포인터의 끝을 가리키고 있는데, x++을 통해 포인터를 증가시킨 후 참조하면, 배열이 아닌 임의의 메모리를 읽게 된다. 싸이클론은 이 문제를 해결하기 위해 뚱뚱한 포인터(fat pointer)라는 개념을 도입하였다. 다음 그림을 살펴보자.
뚱뚱한 포인터는 일반 포인터와 달리 배열의 처음과 끝, 현재를 모두 가리킨다. q++을 통해 포인터의 값을 증가시키면 현재 포인터(c)만 다음으로 변하고 처음과 끝을 그대로다. 따라서 배열의 경계를 넘어가는 포인터 연산의 경우 오류를 발생시킬 수 있게 된다. 물론 이 방식은 큰 런타임 오버헤드가 있다. 특히 루프처럼 반복적으로 배열 값을 읽는 경우 반복된 체크의 오버헤드는 프로그램 수행 속도를 크게 떨어뜨린다. 싸이클론은 기존 포인터와 같은 날씬한 포인터(thin pointer) 또한 제공한다.
이와 유사한 문제는 NULL 값과 관련해서도 발생한다. 주로 NULL 포인터를 참조해서 발생하는 공포의 메모리 오류(segmentation fault)는 C 언어 개발자라면 피해갈 수 없는 숙명이다. 다음과 같은 간단한 파일 IO 프로그램을 살펴보자.
NULL 검사가 없는 파일 IO
int foo(char ?filename, char ?buf) {
FILE *fp;
fp = fopen(filename, "r");
fread(fp, buf);
}
이 간단한 프로그램은 파일 열기에 실패했을 경우 프로그램 크래시(crash)가 발생한다. NULL 검사 없이 fread를 호출하였기 때문이다. 싸이클론 포인터는 int *와 int *@notnull로 나뉜다. int *@notnull은 줄여서 int @라고 쓰기도 하는데, 이 포인터는 절대 NULL이 될 수 없다는 뜻이다. NULL을 넘겼을 때 오류가 발생하는 fread와 같은 함수는 인자를 @로 선언해서 프로그래머가 반드시 NULL 검사를 하도록 만들 수 있다.
싸이클론 버전
struct FILE;
extern FILE *fopen(char ?name, char ?mode);
extern int putc(char, FILE@);
void foo() {
FILE *f = fopen("/tmp/bar.txt", "+wb");
char s[] = "hello";
int i;
for (i = 0; i < 5; i++) { putc(s[i], (FILE @)f); }
위 프로그램에서 putc 함수는 두 번째 인자로 FILE *@notnull을 받으므로, FILE은 NULL이 될 수 없다. foo()의 FILE *f는 FILE * 타입이므로 FILE @와 달라서 컴파일 타임에 타입 오류가 발생한다. (File @)f 는 FILE *를 FILE @로 캐스팅해 줄 뿐만 아니라 런타임 NULL 검사도 추가해준다. 따라서 파일이 없다고 프로그램이 크래시 되는 대신에 자바처럼 예외가 발생하게 되는 것이다.
정리
지금까지 싸이클론의 기능 한 가지를 살펴보았다. 싸이클론은 이보다 훨씬 방대한 언어이다. 싸이클론에서 메모리 할당은 리전 기반 타입 시스템(region based type system)을 사용해서 힙과 스택 영역 등의 포인터를 서로 다른 타입으로 구분한다. 또 각종 현대 타입 시스템 이론을 적절히 활용하여 C 언어의 부족함을 메워주고 있다.
필요는 발명의 어머니라는 말이 있다. C 언어의 부족함과 새로운 언어에 대한 필요성은 앞으로도 여러 가지 언어를 낳을 것이다. 싸이클론은 그런 언어의 하나로 아직 널리 사용되고 있지는 않다. 하지만 저수준 프로그래밍의 고충을 경험한 개발자라면 중요 시스템의 일부 영역만이라도 싸이클론의 적용을 고려해보기 바란다. 추가 정보는 최근에 통합된 싸이클론
홈페이지에서 얻길 바란다.