요즘은 자바 플랫폼과 .NET을 보면 다중 언어 지원이 대세다. 개발자가 하나의 프로그래밍 언어에 얽매여 있을 필요가 없는 시대가 왔다. 그런데 웹 클라이언트 프로그래밍만은 예외다. 어떤 개발자도 예외 없이 자바스크립트를 쓰도록 강요받고 있기 때문이다. 자바스크립트 나름의 매력에도 불구하고 웹 클라이언트 프로그래밍에 다른 언어를 쓰고자 하는 욕망이 있다 구글의 GWT, 280Slides의 Objective-J 등은 웹 클라이언트 프로그래밍에 각각 자바와 Objective-C라는 기존 언어를 쓰고자 하는 시도다. 이 글에서는 자바스크립트의 대안으로 사용되는 웹 클라이언트 프로그래밍 언어들을 살펴보려 한다.
마이크로소프트웨어 2008년 9월 기고글입니다.
새로운 웹 클라이언트 프로그래밍 언어
과거에는 프로그래밍 언어 하나로 전체 시스템을 만드는 방식이 일반적이었다. 하지만 스크립트 언어, 함수 언어 등의 필요성과 장점이 부각되면서 하나의 시스템을 만드는 데 여러 언어를 동시에 쓰는 방법이 인기를 얻고 있다. 예를 들어, 주요 컴포넌트는 자바로 작성하고 컴포넌트 통합 및 사용자 인터페이스 작성은 그루비로 하는 방식은 각 언어의 특징을 잘 살린 실용적인 접근법이다.
처음부터 다중 언어 지원을 중요한 기능으로 내세웠던 .NET은 현재 C#, VB.NET 외에도 IronPython, IronRuby, F#을 비롯해 수십 개의 프로그래밍 언어를 지원하고 있다. .NET에 대응하여 다빈치 머신(Davinci Machine) 프로젝트를 통해 다중 언어 지원을 강화하고 있는 자바 플랫폼도 그루비, Jython, JRuby, 스칼라 등의 자바가상머신 언어 개발을 적극적으로 후원하고 있다. 프로그래밍 언어의 중요 개발자들은 마이크로소프트와 썬 썬마이크로시스템즈가 영입해 개발 속도를 높이고 있다.
이런 변화의 바람 속에도 꿋꿋이 단일 언어만 고집하는 분야가 웹 클라이언트 프로그래밍이다. Ajax 바람 속에 웹 프로그래밍이 서버에서 클라이언트로 추가 넘어가고 있지만 자바, 파이썬, 루비를 포함한 서버의 다양한 개발 언어와 달리 클라이언트 프로그래밍은 오직 자바스크립트만이 유일한 대안이다. 대신 jQuery, Dojo, Prototype 등의 Ajax 라이브러리들은 각자의 취향에 따라 여러 속임수로 다른 언어를 흉내 내고 있다.
하지만 시간이 흐르면서 웹 클라이언트 프로그래밍에 새로운 언어들이 등장하기 시작했다. 대표 선수는 자바를 웹 프로그래밍에 사용한 구글의 GWT(Google Web Toolkit)다. 웹 프레젠테이션 도구인 280Slides 작성에 쓰인 Objective-J도 유명하다. 그 외에도 아직 프로토타입 수준이지만 루비, 파이썬 등 현존하는 거의 모든 언어가 모두 웹에서 돌아가는 시대가 열렸다.
이들 언어는 기존 웹브라우저에서 그대로 동작한다. 비법은 컴파일러에 있다. GWT의 경우 GWT 컴파일러가 자바로 작성된 소스 코드를 컴파일해서 자바스크립트를 생성한다. 일반적인 컴파일러는 고급 언어를 컴파일해서 중간 언어 혹은 기계 코드를 생성하는데 비해 웹 프로그래밍 언어 컴파일러는 최종 코드가 자바스크립트라는 차이만 있을 뿐 기본적인 컴파일러 동작 방식은 동일하다. 컴파일러 기술에 웹 클라이언트 프로그래밍 언어의 새로운 지평을 열었다.
GWT(Google Web Toolkit)
Ajax 프로그래밍은 구글의 대표 기술이다. 지메일(Gmail), 구글맵(Google Maps) 등 구글 대표 서비스는 Ajax 기술을 활용한 풍부한 사용자 인터페이스를 제공하였고 경쟁자들을 물리칠 수 있었다. 누구보다 자바스크립트를 많이 사용하는 구글이 자바스크립트가 아닌 자바로 웹 프로그래밍 툴킷을 제작했다. 구글이 밝힌 GWT의 장점은 컴파일러 최적화를 이용한 고성능 자바스크립트, 개발 도구 지원, 구글 API 및 재사용 UI 컴포넌트다.
GWT의 기본 가정은 손으로 작성한 자바스크립트 코드보다 자바로 작성한 후 컴파일러가 최적화하는 편이 성능이 더 좋다는 것이다. 물론 자바스크립트에 정통한 개발자는 최고의 성능을 발휘하는 아름다운 코드를 작성할 수도 있겠다. 하지만 C 언어가 아닌 어셈블리를 써야만 최고의 성능을 발휘할 수 있으니 무조건 어셈블리만 사용하자는 말과 동일하다. GWT는 자바 코드 컴파일해 얻은 자바스크립트 코드가 손으로 작성한 자바스크립트 코드보다 더 빨리 로딩되면서 코드 크기는 오히려 작다고 이야기한다.
이식성도 중요한 이유다. 자바스크립트는 이식성이 나쁜 언어다. 웹브라우저마다 자바스크립트 인터프리터, DOM, 이벤트 등이 미묘하게 다르고 브라우저 간 호환성을 위해서는 상당한 노력이 필요하다. 물론 고급 Ajax 라이브러리가 이 문제를 상당히 해결한 것은 사실이지만 GWT는 이 문제를 더 높은 수준에서 해결했다. GWT 개발자는 GWT 개발 환경 하나만 익히면 모든 브라우저에서 호환되는 코드를 자동으로 만들 수 있게 된다.
GWT가 자바를 선택한 또 다른 이유는 개발 도구 지원이다. 자바는 이클립스(Eclipse)라는 세상에서 가장 강력한 개발 도구를 보유한 언어이다. 물론 개발자 개인 취향에 따라 IntelliJ 혹은 NetBeans를 선택할 수도 있다. 반대로 자바스크립트는 개발 도구 지원이 열악하다. 동적 타입 시스템을 쓰는 스크립트 언어 특징상 개발 도구 개발이 어렵기 때문이다. 크고 복잡한 응용 프로그램 개발의 경우 개발 도구 지원 여부는 프로그래밍 언어 선택의 중요 기준이 된다.
GWT은 재밌는 기능 중 하나는 JSNI(JavaScript Native Interface)이다. 원래 자바는 JNI(Java Native Interface)라고 해서 자바로 작성된 프로그램이 C 함수를 호출할 수 있는 인터페이스를 열었다. GWT는 웹 브라우저에서 돌아가는 코드를 생성하므로 C 코드를 호출할 수는 없는 대신 자바스크립트 코드를 호출할 수 있게 했는데 그 인터페이스가 JSNI다. 특정 브라우저에만 있는 기능을 이용하거나 GWT가 생성한 코드보다 더 효율적인 코드를 자바스크립트로 작성할 수 있다고 판단했을 때 쓰면 된다.
GWT를 사용한다고 모든 자바 프로그램이 웹에서 실행되지는 않는다. GWT는 자바 언어를 사용하지만 JRE(Java Runtime Environment)를 모두 제공하지는 않기 때문이다. GWT는 JRE의 일부를 웹으로 포팅했고 웹 프로그래밍을 위한 별도의 API를 제공한다. 또한 UI를 쉽게 만들 수 있도록 기존 스윙(Swing) 혹은 SWT와 유사한 UI API도 제공한다. UI 렌더링을 할 때는 HTML을 동적으로 생성하여 붙이는 방식을 쓴다.
Objective-J
Objective-J를 이용해 만든 프레젠테이션 도구 280slides
GWT가 데스크톱 프로그래밍의 일부를 웹 프로그래밍에 도입한 프로젝트라면 Objective-J와 Cappuccino는 데스크톱 프로그래밍 환경을 웹에 그대로 옮겨놓은 야심찬 프로젝트다. Objective-J는 그 이름에서 알 수 있듯이 Mac OS X 데스크톱 응용 프로그램 개발에 사용되는 Objective-C를 웹으로 옮겨놓은 버전이다. Objective-J를 만든 North280은 웹 프레젠테이션 도구(MS의 파워포인트, 애플의 키노트)인 280Slides 통해 Objective-J의 가능성을 보여줬다. Cappuccino는 Mac OS X UI 라이브러리인 Cocoa를 웹으로 포팅한 것이고 역시 North280 팀이 만들었다.
웹 프로그래밍 하면 떠오르는 모습은 Rails, Django 등의 웹 프레임워크로 서버 측 프로그램을 작성하고 HTML, CSS, Ajax 라이브러리로 클라이언트 프로그램을 만드는 방식이다. 하지만 서버 쪽 코드를 줄이고 데스크톱 응용 프로그램과 유사한 웹 응용 프로그램을 만들려는 시도도 계속되고 있다. 대표적인 예가 SproutCore이다. 플래시나 실버라이트가 표방하는 리치 클라이언트(rich client)의 자바스크립트 버전인 셈이다. SproutCore 프로그램은 대부분의 시간을 웹 서버와 독립적으로 동작하다가 데이터를 저장하거나 불러올 때만 Ajax 라이브러리로 서버와 통신하는 방식을 사용한다. SproutCore로 작성된 프로그램은 Rails 웹 응용 프로그램보다는 데스크톱 Cocoa 프로그램을 더 닮았다.
이런 변화의 바람 속에서 웹 프로그램이 Rails 보다 Cocoa 프로그램을 더 닮았다면 자바스크립트가 아닌 Objective-C로 코딩하자는 생각에서 출발한 프로젝트가 Objective-J다. Objective-J의 예는 프로그래밍 언어는 단순한 문법이 아니라 그 언어를 사용하는 사람, 문화, 기술을 통칭함을 보여준다. Objective-J 도입은 자바스크립트, CSS, HTML, DOM을 이용한 전통적 웹 응용 프로그램 개발 방식을 대체하는 데스크톱 스타일의 개발 환경을 웹으로 가져온다.
Objective-J는 North280 팀에 의해 조만간 오픈소스화될 예정이다. Objective-J (http://objective-j.org/) 홈페이지를 확인해 보기 바란다.
Flapjax
앞서 언급한 GWT나 Objective-J는 기존 프로그래밍 언어를 웹으로 포팅하고 각 언어의 장점을 살려 데스크톱 응용 프로그램을 쉽게 구축할 수 있는 방법을 제공했다. 반면에 Flapjax는 새로운 웹 프로그래밍 모델을 제시하는 프로그래밍 언어다.
자바스크립트 프로그래밍의 문제점 중 하나는 콜백 함수 등록이 너무 많다는 점이다. 마우스 위치를 따라 네모 박스가 약간 시간 간격을 두고 따라오는 간단한 자바스크립트 프로그램을 생각해보자. 다음과 같은 HTML, 자바스크립트 코드가 필요할 것이다.
<div id="box" style="position:absolute; background:yellow;">
Seconds to deadline: <span id="time">...time...</span>
</div>
<script>
document.addEventListener(
'mousemove',
function(e) {
var left = e.pageX
var top = e.pageY
setTimeout(function() {
document.getElementById("box").style.top = top;
document.getElementById("box").style.left = left;
}, 500);
}, false);
</script>
자바스크립트 예제
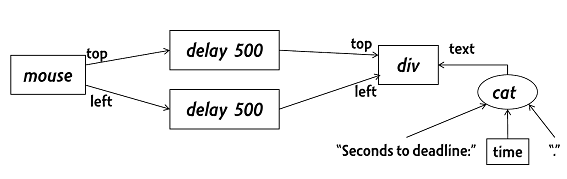
자바스크립트 프로그래밍에 익숙한 개발자는 위 코드가 직관적이라고 느낄 수도 있겠다. 하지만 마우스 위치에 따라 네모 상자를 옮기는 간단한 일을 하기 위해 콜백을 2번 등록하고 "box" ID를 찾아서 값을 변경해야 한다. 가독성도 떨어진다. 이 프로그램은 마우스의 움직임에 따라 다음 그림과 같은 명확한 데이터 흐름이 있지만 위 자바스크립트 소스 코드만 보고 이 사실을 한 번에 알아내기는 쉽지 않다.

데이터 흐름도(data flow)
Flapjax는 이처럼 자바스크립트(Ajax) 프로그램에서 빈번히 발생하는 데이터 흐름 중심으로 프로그램을 기술하는 언어다. 위 프로그램은 Flapjax로 작성하면 다음과 같다. Flapjax는 자바스크립트와 유사한 문법을 가지며 자바스크립트로 컴파일된다.
<div style={!
{
position:"absolute", background: "yellow",
top: delay(mouseTop(), 500),
left: delay(mouseLeft(), 500)
}
!}
> Seconds to deadline: {! timeStream() !}. </div>
Flapjax 예제 (주의: 설명을 위해 간단하게 만들었기 때문에 실제 동작하지 않음)
이 프로그램을 해석하는 방법은 간단하다. mouseTop()과 mouseLeft()는 지속적으로 현재 마우스의 위치를 주는 데이터 소스로 생각하면 된다. top 값은 mouseTop 값이 바뀜에 따라 지속적으로 변경되는데, 변경 시에는 500ms의 지연이 있다. 마찬가지로 left 값은 mouseLeft() 값이 바뀜에 따라 지속적으로 바뀌고 500ms의 지연이 있다. timeStream()은 흐르는 시간을 데이터 소스로 주기 때문에 화면에 표시되는 시간이 계속 바뀐다.
Flapjax는 지속적으로 값이 변경되는 데이터 소스가 존재하고 이 값이 변하면 여기에 의존하는 값들이 자동으로 변경되는 방식을 채택했다. 따라서 일반적인 자바스크립트 프로그래밍처럼 변경이 예상되는 이벤트에 일일이 콜백을 걸어줄 필요 없이도 자동으로 새로운 값이 계산된다. Flapjax 프로그래밍 모델에서는 데이터 흐름이 명시적으로 보이는 것이 장점이고 document.getElementByID를 이용해 변경할 노드를 찾을 필요 없을 값을 삽입할 위치에 직접 코드를 적어주면 된다.
핫루비(HotRuby)
컴파일러 외에 웹에서 다중 언어를 구현하는 또 다른 방식은 자바스크립트로 가상 머신을 구현하는 것이다. 예를 들어 자바가상머신(JVM)을 자바스크립트로 작성하면 자바 프로그램을 바이트코드로 컴파일한 후에 자바스크립트로 돌릴 수 있다. 물론 가상머신은 보통 성능을 높이기 위해 효율적인 C/C++ 코드로 작성하는 것이 일반적이지만 이론적으로는 자바스크립트로 작성해도 아무런 문제가 없다.
핫루비 프로젝트는 루비 인터프리터를 자바스크립트로 구현하는 프로젝트다. Ruby 1.9 YARV(Yet Another Ruby VM)의 바이트코드 인터프리터를 만들었다. <script type="text/ruby"></script> 태그 안에 루비 코드를 작성해 넣으면 텍스트를 뽑아서 XMLHttpRequest로 서버에 보낸다. 서버 CGI는 루비 코드를 받아서 바이트코드로 바꾸고 직렬화해 JSON으로 보낸다. 브라우저는 루비 인터프리터를 돌려서 루비 코드를 실행한다. 핫루비는 기존 코드를 재활용하기 위해 루비 컴파일러를 서버에 두는 방식을 택했지만 이론적으로는 루비 컴파일러 또한 자바스크립트로 만들어 넣을 수 있다.
존 레시그(John Resig)는 다음 코드로 핫루비의 성능을 측정했다[3]. 벤치마크 결과 Ruby 1.8.2에서는 12.25초가 걸렸다. 자바스크립트로 구현한 핫루비의 성능은 어느 정도 일까? 놀랍게도 파이어폭스 2에서 6.71초, 파이어폭스 3.0b5에서 2.47초 만에 수행이 끝났다. C로 구현한 Ruby 1.8.2 보다 자바스크립트로 구현한 핫루비가 몇 배나 더 빠른 셈이다. 게다가 파이어폭스 버전이 올라갈수록 더 빨라지고 있다.
startTime = Time.new.to_f
sum = ""
50000.times{|e| sum += e.to_s}
endTime = Time.new.to_f
puts (endTime - startTime).to_s + ' sec'
루비 벤치마크
["YARVInstructionSequence\/SimpleDataFormat",1,1,1,{"arg_size":0,"local_size":4,"stack_max":3},"","src","top",["startTime","sum","endTime"],0,[["break",null,"label_21","label_29","label_29",0]],[2,["putnil"],["getconstant","Time"],["send","new",0,null,0,null],["send","to_f",0,null,0,null],["setlocal",4],4,["putstring",""],["setlocal",3],"label_21",5,["putobject",50000],["send","times",0,["YARVInstructionSequence\/SimpleDataFormat",1,1,1,{"arg_size":1,"local_size":1,"stack_max":2},"block in ","src","block",["e"],[1,[],0,0,-1,-1,3],[["redo",null,"label_0","label_22","label_0",0],["next",null,"label_0","label_22","label_22",0]],["label_0",5,["getdynamic",3,1],["getdynamic",1,0],["send","to_s",0,null,0,null],["send","+",1,null,0,null],["dup"],["setdynamic",3,1],"label_22",["leave"]]],0,null],"label_29",["pop"],7,["putnil"],["getconstant","Time"],["send","new",0,null,0,null],["send","to_f",0,null,0,null],["setlocal",2],9,["putnil"],8,["getlocal",2],["getlocal",4],["send","-",1,null,0,null],["send","to_s",0,null,0,null],["putstring"," sec"],9,["send","+",1,null,0,null],["send","puts",1,null,8,null],8,["leave"]]]
서버가 생성해 JSON으로 준 핫루비 바이트코드
상식적으로 납득하기 어려운 벤치마크 결과를 설명하기 위해서는 Ruby 1.8.2와 Ruby 1.9의 차이를 알아야 한다. Ruby는 인터프리터가 비효율적인 것으로 유명한 스크립트 언어다. 동일한 일을 수행하는 코드를 작성하면 C 보다 100배 이상 느린 경우가 다반사다. 파이썬이 소스코드를 일단 중간 코드(바이트코드)로 변환한 후에 인터프리트하는 것과 달리 루비는 1.8.2까지 파싱된 소스 코드(AST)를 매번 새로 방문하면서 코드를 실행하는 방식을 택했기 때문이다. YARV는 이런 문제를 해결하기 위해 루비에 바이트코드 인터프리터를 추가하는 프로젝트였고 루비 1.9는 YARV를 기본으로 채택했다. 핫루비는 바이트코드 인터프리터이기 때문에 루비 1.8.2의 비효율적인 실행 방식에 비해 빠르다.
핫루비의 성능이 괜찮은 또 다른 요인은 자바스크립트 인터프리터가 점점 빨라지고 있다는 점이다. 파이어폭스 2.0과 3.0b5의 비교를 해보면 3.0b에서 2.71배 속도 향상이 있음을 볼 수 있다. 앞서 언급한 GWT, Objective-J 등 대형 Ajax 프레임워크가 나오면서 자바스크립트 속도 향상이 브라우저 벤더들 사이에서 중요한 요구사항이 되었기 때문이다.
모질라는 파이어폭스의 성능을 더 높이기 위해 현재 아도브가 기증한 타마린(Tamarin) 스크립트 엔진을 파이어폭스 스크립트 엔진인 스파이더몽키(SpiderMonkey)에 붙이는 액션몽키(ActionMonkey) 프로젝트를 진행하고 있다. 그것만으로 모자랐는지 아도브는 타마린에 바이트코드 실행 기록을 남겨서 머신 코드를 생성하는 트레이스 JIT를 추가한 타마린 트레이싱(Tamarin Tracing)까지 내놓고 자바스크립트 속도를 높이기 위해 안간힘을 쓰고 있다.
이런 움직임은 애플 사파리에서도 마찬가지다. 애플은 최근 레지스터 바이트코드를 쓰는 다이렉트 쓰레드(direct-threaded) 코드 기반의 효율적인 자바스크립트 엔진 인터프리터인 스쿼럴피시(SquirrelFish)를 내놨고, 그 속도는 JIT 컴파일러를 내장한 타마린을 능가하고 있다. 스쿼럴피시는 앞으로 사파리에 탑재되어 데스크톱 사파리와 iPhone 사파리 모바일 등에 사용될 예정이다.
정리
웹 프로그래밍은 서버에서 클라이언트로 이동하고 있다. 플래시, 실버라이트, JavaFX 등 비표준 RIA 플랫폼 이런 변화를 앞당긴 기술이다. 웹 표준 기반 응용 프로그램도 서서히 서버에서 클라이언트로 방향 전환을 하고 있다. 따라서 Ajax로 대표되는 웹 클라이언트 프로그래밍의 중요성이 날로 커지고 있다.
앞서 살펴본 것처럼 웹 클라이언트 프로그램이 발전하고 데스크톱 응용 프로그램과 유사한 기능을 원하게 되면 기존 데스크톱 응용 프로그램에 작성에 사용되는 프로그래밍 언어와 라이브러리들이 웹으로 진입할 가능성이 크다. 컴파일러 혹은 VM 기술에 힘입어 기존 브라우저를 수정하지 않고도 다양한 언어를 지원할 수 있기 때문이다.
따라서 앞으로 웹 개발자는 빠르고 효율적인 개발을 위해 서버 기반 웹 프레임워크에서 벗어나 클라이언트 솔루션을 찾아볼 필요가 있다. GWT, Objective-J, Flapjax 등의 새로운 웹 프로그래밍 언어 및 프레임워크는 웹 응용 프로그램 작성에 있어 든든한 지원군이 되어줄 것이다.
참고문헌
[1] GWT(Google Web Toolkit) Documentation
http://code.google.com/webtoolkit/overview.html
[2] Flapjax Tutorial
http://www.flapjax-lang.org/tutorial/
[3] Ruby VM in JavaScript
http://ejohn.org/blog/ruby-vm-in-javascript/