자바 컴파일러 들여다보기
Posted 2008. 11. 30. 02:12마이크로소프트웨어 2006년 7월 기고글입니다.
T 업계의 종사하는 사람이라면 18개월마다 컴퓨팅 파워가 2배가 된다는 무어(Moore)의 법칙을 잘 알고 있을 것이다. 컴파일러에도 이와 비슷한 법칙이 있다.
Proebsting's Law
컴파일러 기술은 18년마다 컴퓨팅 파워(computing power)를 2배로 증가시킨다.
이 법칙이 정확한 예측치는 아니더라도 비약적으로 발전하는 하드웨어에 비해 컴파일러의 발전 속도가 상당히 더디다는 것만은 유추할 수 있다. 하지만 그렇다고 마냥 정체되어 있기만 한 것은 아니었다. 50-60년대에 최초의 컴파일러가 나오고 벌써 수십 년이 지났으므로, 지금 우리가 사용하는 컴파일러는 초창기에 비해 상당히 발전한 것이다.
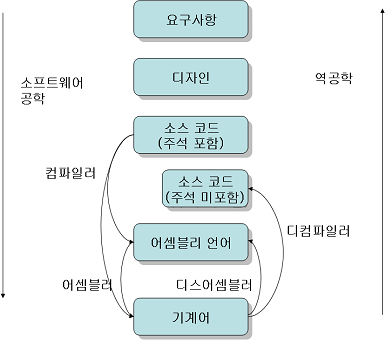
따라서 개발자도 컴파일러를 블랙박스로만 생각할 것이 아니라, 어떤 일을 해주는지 조금은 알아둘 필요가 있다. 컴파일러가 변환하는 소스 코드와 바이너리의 관계를 코드 모양(code shape)이라고 하는데, 최적화 컴파일러의 복잡한 변환(transformation) 과정은 아니더라도, 이런 코드 모양을 몇 가지 숙지하고 있으면 좋다. 이 글에서는 자바의 표준 컴파일러인 javac을 통해 자바 언어와 바이트코드에 대한 이해의 폭을 넓혀 보려고 한다.
데드 코드(dead code)와 조건부 컴파일
C/C++ 개발자들이 자바 개발을 시작하면 가장 먼저 느끼는 불편함 중에 하나가 전처리기(preprocessor)의 부재일 것이다. C/C++에서는 #ifdef #endif를 이용해서 특정 코드를 선택적으로 컴파일할 수 있는데, 자바는 그런 전처리기가 없기 때문이다. 하지만 자바 컴파일러를 잘 이용하면 자바에서도 조건부 컴파일이 가능하다. 우선 자바 컴파일러의 배경 지식부터 살펴보자.
컴파일러는 바이너리를 생성하기에 앞서서 실행 흐름 분석(control flow analysis)을 통해 소스 프로그램을 분석하는데, 이 분석을 통해 하는 일 중에 하나가 데드 코드 제거(dead code elimination)이다. 자바 컴파일러도 프로그램 흐름상 절대로 수행될 수 없는 코드를 발견하면 이 부분은 바이트코드에 포함시키지 않는다. 다음 예제를 보자.
public class Foo {
public static void main(String args[]) {
if (false) {
System.out.println("Never");
}
}
}
데드 코드 예제
자바 디컴파일러 javap
자바 개발 환경을 설치하면 javac, java와 함께 몇 가지 프로그램이 함께 설치되는데, 그 중 하나가 자바 디컴파일러인 javap이다. javap는 클래스 파일을 읽어서 클래스와 메쏘드, 그리고 각 메쏘드의 바이트코드를 보여주는 프로그램이다. 특히 자바 네이티브 인터페이스(Java Native Interface, JNI) 작성 시에 메쏘드 시그너처(signature)를 뽑아내는데 유용한 도구이다. -c 옵션을 주면 각 메쏘드의 바이트코드도 볼 수 있는데, 이 글의 디컴파일 결과는 모두 javap -c를 사용한 것이다.
위 코드에서 if (false) System.out.println("Never")은 수행될 수 없는 코드이다. 따라서 바이트코드에 포함되지 않는데, 자바 디스어셈블러인 javap를 이용해 Foo.class를 살펴보면 main 메쏘드에 return 문만 있는 것을 볼 수 있다.
public static void main(java.lang.String[]);
Code:
0: return
데드 코드 Foo의 디컴파일
물론 if (false)의 경우는 너무 당연해서 별로 쓸모가 있어 보이지 않는다. 하지만 자바 컴파일러가 데드 코드를 바이트코드에 포함시키지 않는다는 사실을 이용하면 C/C++ 전처리기리처럼 조건부 컴파일을 흉내 낼 수 있다. 다음 예제를 살펴보자.
class Configure {
public static final boolean debug = false;
}
public class Foo {
public static void main(String args[]) {
if (Configure.debug) {
System.out.println("Debug.");
}
}
}
조건부 컴파일 예제
[debug가 static final인 경우]
public static void main(java.lang.String[]);
Code:
0: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3; //String Debug.
5: invokevirtual #4; //Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
조건부 컴파일 디컴파일
자바에서 static final로 선언된 필드는 상수(constant)이다. 따라서 위 조건부 컴파일 예제의 경우 Configure.debug라는 플래그가 false이면 main 메쏘드의 if (Configure.debug) 부분이 데드 코드가 되므로 바이트코드에 포함되지 않는다. 반대로 debug를 true로 바꿔주면, if (Configure.debug) 부분 코드가 컴파일되는데, debug는 static final로 선언되어 있으므로 항상 참이다. 따라서 javac은 if 문을 없애고 바로 System.out.println을 실행하도록 코드를 생성한다. 즉 flag를 true/false로 바꿔준 후에 새로 컴파일하면 조건부 컴파일이 되는 것이다.
[debug가 final이 아닌 경우]
public static void main(java.lang.String[]);
Code:
0: getstatic #2; //Field Configure.debug:Z
3: ifeq 14
6: getstatic #3; //Field java/lang/System.out:Ljava/io/PrintStream;
9: ldc #4; //String Debug.
11: invokevirtual #5; //Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: return
final이 아닌 경우 디컴파일
만약에 debug가 final이 아니었다면 런타임에 값이 바뀔 수 있으므로, [debug가 false가 아닌 경우]의 3행에서처럼 ifeq로 debug 값을 테스트하는 부분이 들어갔을 것이다.
배열 초기화(array initialization)
C/C++ 프로그램을 개발할 때 바이너리 데이터를 메모리에 읽어오는 방법으로 배열 초기화를 사용하는 경우가 많다. 특히 바이너리 외에 별도의 파일 시스템이 없는 임베디드 시스템의 경우 어플리케이션의 그림(image)나 소리(sound) 데이터를 char[]에 저장한다. 로더(loader)가 프로그램을 로드할 때 배열의 값을 메모리의 데이터 영역으로 바로 복사해주기 때문에 효율적이다.
다음은 썬(Sun)에서 만든 J2ME의 Personal Basic Profile 소스 코드에서 발췌한 코드이다.
class IxcClassLoader extends ClassLoader {
/* fields */
private static byte[] utilsClassBody = { // The .class file
(byte) 0xca, (byte) 0xfe, (byte) 0xba, (byte) 0xbe,
(byte) 0x00, (byte) 0x00, (byte) 0x00, (byte) 0x2e,
(byte) 0x00, (byte) 0x3d, (byte) 0x0a, (byte) 0x00,
(byte) 0x11, (byte) 0x00, (byte) 0x1f, (byte) 0x07,
(byte) 0x00, (byte) 0x20, (byte) 0x07, (byte) 0x00,
(byte) 0x21, (byte) 0x0a, (byte) 0x00, (byte) 0x03,
(byte) 0x00, (byte) 0x22, (byte) 0x0a, (byte) 0x00,
(byte) 0x02, (byte) 0x00, (byte) 0x23, (byte) 0x0a,
(byte) 0x00, (byte) 0x02, (byte) 0x00, (byte) 0x24,
(byte) 0x07, (byte) 0x00, (byte) 0x25, (byte) 0x07,
(byte) 0x00, (byte) 0x26, (byte) 0x07, (byte) 0x00,
(byte) 0x27, (byte) 0x0a, (byte) 0x00, (byte) 0x08,
...
PBP의 IxcClassLoader 클래스
이 코드를 보면 utilsClassBody라는 byte[] 필드에 클래스 생성에 필요한 유틸리티 클래스의 바이트코드를 바이너리 형태로 넣어 놨음을 알 수 있다. static 필드이므로 클래스 정적 초기화(static initialization)시에 해당 필드가 초기화될 것이다. C/C++ 코드를 많이 작성해온 개발자라면 이런 형식의 배열 사용법에 익숙할 것이다. 자바에서 이런 배열 초기화의 문제점은 무엇일까? 대답에 앞서서 이 클래스를 한 번 디컴파일해보자.
static {};
Code:
0: sipush 1165
3: newarray byte
5: dup
6: iconst_0
7: bipush -54
9: bastore
10: dup
11: iconst_1
12: bipush -2
14: bastore
15: dup
16: iconst_2
17: bipush -70
19: bastore
20: dup
21: iconst_3
22: bipush -66
24: bastore
25: dup
26: iconst_4
27: iconst_0
28: bastore
29: dup
...
PBP의 IxcClassLoader 클래스 디컴파일
무엇이 문제인지 감이 잡히는가? 지면 관계상 일부만 표시했지만, byte[] utilsClassBody는 길이가 1165이다. C/C++이였으면 이 데이터를 곧바로 메모리에 로드하였겠지만, 자바의 클래스 로더는 그렇지 않다. 자바의 경우 클래스를 초기화할 때 1165 길이의 byte[]를 힙에 생성하고 각 원소를 하나하나 초기화해주어야 한다. 이 초기화를 위해서 무려 7738개의 바이트코드가 필요하다. 코드 길이도 문제지만, 클래스 로딩 시간 또한 무척 길어진다.
자바의 원산지인 썬에서 배포하는 코드에서 이런 문제점이 있다는 점을 생각해보면 언뜻 비슷해 보이는 두 언어의 차이점을 정확히 알고 쓰는 일이 쉽지 않음을 알 수 있다.
문자열 처리
자바는 문자열의 편리한 처리를 위해서 문자열 병합 연산자(+)를 제공한다. 따라서 우리는 "Hello" + "World"와 같이 문자열을 병합할 수 있고, "I am " + name + "."과 같이 중간에 변수를 삽입해서 문자열을 생성할 수도 있다.
하지만 자바의 String 클래스는 변경 불가능(immutable)한 클래스이다. 따라서 한 번 문자열을 생성하면 문자열의 값을 바꾸는 것은 불가능하다. 따라서 replace, replaceAll, toLowerCase 등의 메쏘드는 모두 기존의 문자열은 그대로 두고 새로운 문자열을 리턴한다. java.lang.String의 API를 유심히 읽어본 개발자라면 정답을 알고 있을 것이다.
◆ java.lang.String API에서 발췌
문자열 병합은 StringBuilder(혹은 StringBuffer) 클래스의 append 메쏘드를 통해 이루어진다. 추가적인 정보를 위해서는 자바 언어 명세서(Java Language Specification)을 참조하기 바란다.
즉 우리가 String a = "Hello"; a += " World"; 라고 프로그램을 작성하더라도 실제 병합은 StringBuilder 클래스를 통해 이루어짐을 의미한다. 역시 실제 프로그램을 컴파일해서 확인해보도록 하자.
public class Foo {
public static void main(String args[]) {
String h = "Hello";
h += "World";
}
}
public static void main(java.lang.String[]);
Code:
0: ldc #2; //String Hello
2: astore_1
3: new #3; //class java/lang/StringBuilder
6: dup
7: invokespecial #4; //Method java/lang/StringBuilder."<init>":()V
10: aload_1
11: invokevirtual #5; //Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
14: ldc #6; //String World
16: invokevirtual #5; //Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
19: invokevirtual #7; //Method java/lang/StringBuilder.toString:()Ljava/lang/String;
22: astore_1
23: return
String 병합
바이트코드를 잘 모르더라도 String 대신에 StringBuilder 클래스를 통해 문자열을 병합하고 이후에 toString 메쏘드를 이용해 문자열을 돌려줌을 쉽게 유추해 볼 수 있다. 이처럼 javac은 자바 개발자가 알게 모르게 여러 가지 일을 해주고 있는데, 바꿔 말하면 자바 개발자는 의도하지 않게 비효율적인 명령을 실행할 수도 있다는 뜻이다. 실제로 초창기 자바는 멀티 쓰레드 세이프한 StringBuffer의 append 메쏘드를 이용했는데, append는 매번 락을 잡았다 풀었다 하였기 때문에 심각한 속도 저하의 원인이 되기도 했었다.
Inner Class
이너 클래스가 있는 클래스를 컴파일하면, $ 표시가 붙은 클래스 파일이 생성되는 것을 보았을 것이다. 그리고 JVM 명세서를 잘 읽어보면 이너 클래스라는 게 존재하지 않는다는 사실도 알 수 있을 것이다. 그렇다면 다음과 같이 이너 클래스가 있는 클래스를 컴파일하면 어떤 일이 생기는 걸까?
public class Foo {
static class Bar {
private boolean flag = true;
}
public static void main(String args[]) {
Bar bar = new Bar();
System.out.println(bar.flag);
}
}
Inner Class
위 예제의 경우 Foo 내부에 Bar라는 정적 이너 클래스를 선언하였다. Bar는 Foo의 이너 클래스이므로 private 멤버라도 직접 접근이 가능하다. 이 클래스를 컴파일하면 Foo.class와 Foo$Bar.class라는 두 개의 클래스 파일이 나타난다. JVM에는 이너 클래스의 개념이 없으므로, 자바 소스 코드 상에서는 Bar는 Foo의 이너 클래스이지만 바이트코드 상에서는 별도의 클래스가 되는 것이다.
public class Foo extends java.lang.Object{
public Foo();
public static void main(java.lang.String[]);
}
class Foo$Bar extends java.lang.Object{
Foo$Bar();
static boolean access$000(Foo$Bar);
}
Inner Class 디컴파일
또 하나 특이한 점으로는 access$000라는 메쏘드가 있다. 원래 Bar 클래스에는 없는 메쏘드인데 어째서 바이트코드에는 나타난 것일까? 그 이유는 자바 소스 코드에서는 Bar가 이너 클래스이므로 Foo의 main 메쏘드에서 Bar의 private field가 접근 가능해야 하는데, 실제 바이트코드 상에서는 별도의 클래스이므로, private 멤버의 값을 읽을 수 없게 된다. 이 문제를 해결하기 위해 자바 컴파일러는 access$000이라는 메쏘드를 생성해 Foo가 Bar의 필드 참조 시 access$000으로 대체하게 된다.
Enumeration
Java 5에는 타입 세이프 enum 강화된 for 루프, 제네릭스(generics), 오토박싱(autoboxing), 언박싱(unboxing), 가변인자(varargs), 정적 임포트(static import), 메타데이터(metadata) 등 여러 가지 언어 기능이 추가 되었다. 하지만 언어만 바뀌었을 뿐 기존의 JVM이 사용하던 바이트코드에는 차이가 없다. 이 말은 결국 이런 기능들은 전부 컴파일러가 해준다는 뜻이다. 타입 세이프 enum을 통해서 컴파일러가 어떤 바이트코드를 생성해 내는지 살펴보자.
public enum Week {
MON, TUE, WED, THU, FRI, SAT, SUN
}
Week Enum
위 Week enum은 월요일부터 일요일까지 각각의 요일을 나타낸다. enum이 없던 시절에는 어떻게 구현했을까? 한 가지 방법은 int 상수를 이용하는 것이다.
public class Week {
public static final int MON = 0;
public static final int TUE = 1;
public static final int WED = 2;
public static final int THU = 3;
public static final int FRI = 4;
public static final int SAT = 5;
public static final int SUN = 6;
}
int 상수를 이용한 Week Class
이 방법도 동작에는 전혀 문제가 없지만, MON, TUE, WED 같은 값들이 int이기 때문에 MON * 2 같이 의미 없는 연산을 하더라도 컴파일 타임에 타입 에러를 발견할 수 없었다. 이런 문제를 해결하기 위해 타입 세이프 enum 패턴이 널리 쓰였다.
public class Week {
public static final Week MON = new Week();
public static final Week TUE = new Week();
public static final Week WED = new Week();
public static final Week THU = new Week();
public static final Week FRI = new Week();
public static final Week SAT = new Week();
public static final Week SUN = new Week();
}
타입 세이프 enum 패턴
이 방식은 타입 세이프하지만 각 필드가 오브젝트이므로 int를 사용한 방식과는 달리 switch 문에 사용이 불가능하다는 불편함이 있었다. 반면에 Java5에 도입된 타입 세이프 enum은 타입 세이프하면서 switch 문에서도 사용이 가능하다. 어떻게 구현한 것일까? Week enum을 디컴파일해보자.
public final class Week extends java.lang.Enum{
public static final Week MON;
public static final Week TUE;
public static final Week WED;
public static final Week THU;
public static final Week FRI;
public static final Week SAT;
public static final Week SUN;
...
static {};
Code:
0: new #4; //class Week
3: dup
4: ldc #7; //String MON
6: iconst_0
7: invokespecial #8; //Method "<init>":(Ljava/lang/String;I)V
10: putstatic #9; //Field MON:LWeek;
...
타입 세이프 enum 패턴
우리가 간단히 enum Week { MON, TUE, ... }로 써줬지만 실제로 컴파일하면 타입 세이프 enum 패턴처럼 각각이 public final static Week 필드로 들어가 있음을 알 수 있다. 즉 우리가 타입 세이프 enum 패턴에서 수동으로 구현해주던 것을 컴파일러가 대신해 주는 것이다. 클래스 초기화인 static{} 에서는 Week의 객체를 생성해서 각 필드를 초기화해주고 있다. 객체를 생성할 때 MON은 0, TUE는 1, WED는 2 하는 식으로 값을 주고, switch 문에서는 이 값을 얻어오는 ordinal() 메쏘드를 호출하여 switch 문에서도 사용할 수 있게 해준다.
정리
지금까지 자바 컴파일러(javac)가 해주는 몇 가지 일을 살펴보았다. 특히 자바 소스 코드의 특정 구문이 어떤 바이트코드로 변환되는지를 위주로 보았다. 우리는 javap를 이용해 결과를 살펴보았지만, JVM 지식이 있고 자바 언어 명세서를 꼼꼼히 읽은 개발자라면 이미 알고 있었을 내용일지도 모르겠다.
자바 개발자를 만나서 이야기해보면 깜짝 놀라는 일 중에 하나는, 자바의 가장 근간이 되는 자바 언어 명세서(Java Language Specification)와 자바 가상 머신(Java Virtual Machine) 명세서를 숙독한 개발자가 거의 없다는 점이다. 자바 튜토리얼(tutorial)이나 여러 자바 입문서로 시작하여 단 한 번도 명세서를 보지 않고 지금까지 프로그램을 작성해 온 개발자가 부지기수다.
모든 자바 컴파일러, 자바 가상 머신은 모두 이 명세서를 기준으로 만들어졌다. 썬에서 배포하는 레퍼런스 구현(reference implementation)도 결국 이 명세서를 바탕으로 만든 구현 중 하나에 지나지 않는다. 즉 자바 언어 명세서는 자바 세상의 성경인 셈이다. 명세서를 바탕으로 자바의 문법과 의미를 분명히 명확히 이해하고, 자바 코드가 어떤 바이트코드로 변환되는지를 숙지하는 것은 고급 개발자가 되기 위해 반드시 필요한 일이다.
이 과정에서 디컴파일러를 이용해 의문을 해소하는 일은 무척 유용하다. 앞서 언급하지는 않았지만 try, finally 구문은 바이트코드로 어떻게 표현되는지, synchronized 블록은 바이트코드로 어떻게 변환되는지 등을 살펴보면 자바 언어와 JVM에 대한 이해를 넓힐 수 있다. 자바의 경우 컴파일러에 대한 지식은 결국 언어 지식을 넓히는 길인 셈이다.
참고문헌
[1] Java Language Specification, Third Edition Gosling, Joy, Steele, Bracha Addison Wesley 2005
[2] Java Virtual Machine Specification, Second Eidtion Lindholm, Yellin, Addison-Wesley 1999
- Filed under : 카테고리 없음