객체지향+함수형 프로그래밍 언어 Scala
Posted 2008. 12. 1. 00:19마이크로소프트웨어 2008년 5월 기고글입니다.
왜 새로운 언어가 필요했을까?
스칼라 언어를 만든 사람은 GJ, Pizza 프로젝트 등으로 유명한 마틴 오더스키(Martin Odersky)다. 그가 주도한 GJ와 Pizza는 자바 언어에 인자 다형성(parametric polymorphism)을 추가한 리서치 프로젝트였고 이런 결과물은 이후 자바 5의 제네릭스가 되었다. 하지만 JVM을 변경하지 않고 컴파일러 기술만으로 구현한 제네릭스는 성공이라고 보기 힘들었다. 오더스키는 이런 접근법에 한계를 느끼고, 함수 언어의 장점을 적극 반영한 새로운 JVML을 만들었다. 이렇게 나온 결과물이 스칼라이다.
스칼라의 목표는 컴포넌트 소프트웨어를 잘 지원하기 위한 언어이다. 자바는 대규모 개발 프로젝트에 주로 사용되는 언어이고, 각종 프레임워크를 가져와서 조합해 사용하는 경우가 다른 언어보다 압도적으로 많다. 하지만 자바 언어 자체는 소형 디바이스를 지원하기 위한 오크(Oak)라는 프로그래밍 언어에서 출발했고, 웹에서도 소형 애플릿 작성을 주로 사용되었다. 이런 자바를 각종 프레임워크로 포장해 대형 프로젝트에 사용하기 시작하다보니 언어의 한계로 인해 여러 문제점을 겪게 되었다.
컴포넌트 지원 언어는 2가지 특징을 가져야 한다. 첫째, 규모 가변적(scalable)해야 한다. 바꿔 말해, 컴포넌트의 크기와 관계없이 항상 같은 방법으로 사용할 수 있어야 한다는 것이다. 또한, 언어에 복잡한 요소를 더하기 보다는 추상화(abstraction), 조합(composition), 분해(decomposition)에 초점을 맞춰야 함을 의미한다. 둘째, 이런 특징을 만족시키기 위해서 프로그래밍 언어는 객체지향적일 뿐만 아니라 함수형이어야 한다.
HelloWorld
스칼라를 본격적으로 공부하기에 앞서 스칼라의 기본적인 문법과 취향을 느낄 수 있도록 먼저 HelloWorld 프로그램을 작성해보자. 비교를 위해 자바 HelloWorld를 나란히 배치했다.
object HelloWorld {
def main(args: Array[String]) {
println("Hello, world!")
}
}
Scala HelloWorld
class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
Java HelloWorld
일단 가장 큰 차이점으로 HelloWorld 클래스를 선언할 때 스칼라 프로그램은 object라는 키워드를 쓰고 있다. 스칼라는 class와 object를 구분하는데, object는 싱글톤(singleton)으로 클래스의 객체를 하나만 생성함을 의미한다. 스칼라 HelloWorld는 싱글톤이기 때문에 main 메서드를 선언할 때도 static이라는 키워드를 사용하지 않는다.
자바에서는 화면에 문자열을 출력하기 위해 System.out.println을 사용했는데, 스칼라는 간결하게 println이라고 사용할 수 있다. 자바는 문장의 끝에 세미콜론을 항상 붙여줘야 하는데, 스칼라는 세미콜론이 없다. 자바는 타입을 먼저 쓰고 변수를 선언하는데, 스칼라는 변수 : 타입 형태로 변수를 선언한다. 자바에서 String[]인 문자열 배열은 스칼라에서는 Array[String]으로 쓴다.
스칼라 인터프리터와 컴파일러
스칼라를 설치하고 스칼라 바이너리(scala)를 실행시키면 다음과 같이 인터프리터 모드로 동작한다. 인터프리터 모드에서는 입력되는 식을 계산해서 결과를 보여준다. 이후 예제에서 scala>가 나오면 인터프리터에 입력한 것으로 생각하면 된다.
C:\Users\Administrator>scala
Welcome to Scala version 2.7.0-final (Java HotSpot(TM) Client VM, Java 1.6.0_10-
beta).
Type in expressions to have them evaluated.
Type :help for more information.
scala> 3+5
res1: Int = 8
스칼라 인터프리터
스칼라 컴파일러(scalac)는 스칼라 코드를 자바 클래스파일(바이트코드)로 컴파일해준다. 사용법은 자바 컴파일러(javac)와 유사하다. 위 HelloWorld.scala라는 컴파일하려면 다음과 같이 명령을 내려주면 된다.
C:\Users\Administrator>scalac HelloWorld.scala
스칼라 컴파일러
컴파일된 스칼라 프로그램을 실행시키려면 scala를 이용하면 된다.
C:\Users\Administrator>scala HelloWorld
Hello, world!
스칼라 프로그램의 실행
순수 객체지향 언어
자바의 타입은 기본 타입(primitive type)과 레퍼런스 타입(reference type)으로 나뉘고, 이진(boolean), 정수(int), 부동소수점(float, double) 등 기본 타입은 객체가 아니다. 이런 방식은 성능 향상에는 큰 도움이 되지만, 기본 타입과 레퍼런스 타입 사이를 변환하는 박싱(boxing), 언박싱(unboxing) 등의 문제로 프로그래밍 언어가 복잡해지는 문제가 있다.
자바 5에는 기본 타입과 레퍼런스 타입을 필요에 따라 자동변환해주는 오토박싱, 오토언박싱 기능이 들어갔지만, 기본 타입과 레퍼런스 타입으로 이원화된 타입 시스템 자체는 달라지지 않았다.
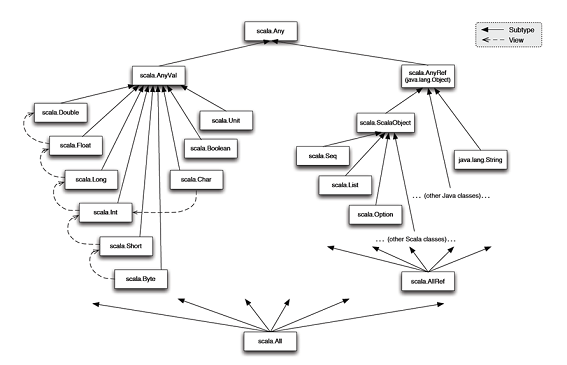
반대로 스칼라는 스몰토크, 루비와 마찬가지로 순수 객체지향 언어이다. 스칼라는 정수 5가 scala.Int 클래스의 객체이며, +, -, , *, / 등의 연산자는 하나의 인자를 받는 메서드다. 예를 들어 1 + 2 * 3 / x 같은 수식은 1.+(2.*3./(x)))와 같이 전부 메서드 호출로 변경된다. 스칼라에서는 자바에서 특수 문자로 취급하던 +, -, *, / 등의 문자도 메서드 이름으로 사용할 수 있음을 의미한다.
아래 그림에서 볼 수 있듯이 스칼라의 클래스 계층도는 scala.Any를 최상위로 해서 값(scala.AnyVal)과 레퍼런스(scala.AnyRef)를 하나의 계층으로 아우르고 있다.
함수 언어
스칼라는 모든 함수를 객체로 취급한다. 바꿔 말해, 스칼라에서 함수를 함수의 인자로 넘길 수도 있고, 함수의 리턴 값으로 함수가 리턴될 수도 있음을 의미한다. 스칼라 입문서에 있는 간단한 예제를 하나 살펴보자.
object Timer {
def oncePerSecond(callback: () => unit) {
while (true) { callback(); Thread sleep 1000 }
}
def timeFlies() {
println("time flies like an arrow...")
}
def main(args: Array[String]) {
oncePerSecond(timeFlies)
}
}
함수를 함수의 인자로 넘기는 예제
위 예제는 Timer라는 클래스를 만들어, main에서 oncePerSecond라는 메서드를 호출할 때 또 다른 메서드인 timeFlies를 인자로 넘겨준 예제이다. oncePerSecond 함수의 인자를 보면 callback이 () => unit이라는 타입을 가짐을 알 수 있는데, ()는 인자를 하나도 받지 않음을 뜻하고, unit은 자바의 void와 유사하게 리턴 값이 없음을 뜻한다. 위 프로그램은 1초마다 한번씩 callback으로 넘어온 timeFlies 메서드를 호출하게 된다.
이 예제에서 하나 재미있는 사실은 Thread의 sleep 메서드를 호출할 때 Thread sleep 1000라고 적은 부분이다. 스칼라에서는 인자가 하나인 메서드를 호출할 때, 메서드 호출자(.)를 생략하고 위와 같이 적을 수 있다. 앞서 +, - 등이 메서드라고 언급했는데 1.+(2)가 아닌 1 + 2로 적을 수 있는 이유도 마찬가지다. 1 + 2에서 1은 리시버 오브젝트(receiver object), +는 메서드, 2는 + 메서드의 인자인데, 스칼라에서는 간결함을 위해 1.+(2)라고 적는 대신에 1 + 2라고 적을 수 있게 허용한 것이다.
정적 타입 시스템
스칼라는 자바에 비해 간결한 문법을 제공하지만, 강력한 정적 타이핑을 제공한다. 스칼라는 동적 JVML 언어인 그루비, JRuby, Jython 등과 달리 컴파일 타임에 모든 타입 오류를 잡아낼 수 있다. 스칼라가 여러 컴포넌트를 통합하기 위해 만들어진 언어라는 점을 감안하면 통합 오류를 조기에 잡아내는 정적 타입 시스템은 자연스러운 선택이다.
대신 스칼라는 같은 정적 타이핑을 사용하는 자바와 달리 경우에 따라 타입을 생략할 수 있다. 사용자가 모든 타입을 적어주지 않더라도 스칼라 컴파일러가 타입 추론(type inference)을 통해 부족한 부분을 채워주기 때문이다. 타입 추론은 자바 스타일의 문법을 가진 스칼라를 동적 타이핑하는 그루비나 루비처럼 간결하게 만들어주는 핵심 요소이다. (스칼라 코드는 같은 일을 하는 자바 코드의 1/3 정도 밖에 안 된다.)
일례로, 정수 2개를 더해서 돌려주는 add 함수를 생각해보자. add 함수를 정의할 때 x와 y는 정수 타입으로 정의를 해줬지만 add 함수의 리턴 타입은 생략했다. 하지만 스칼라 컴파일러가 봤을 때 정수 x와 정수 y를 더한 값을 돌려주므로 리턴 타입은 자동으로 Int가 된다는 사실을 추론해낼 수 있다. 이 함수를 인터프리터에 입력해보면, 인터프리터가 add의 타입을 (Int,Int)Int라고 정확히 추론해냄을 볼 수 있다.
scala> def add(x: Int, y: Int) = x + y
add: (Int,Int)Int
스칼라 타입 추론 (리턴 타입을 추론한 경우)
물론 다음과 같이 타입을 모두 적어줘도 무방하다.
scala> def foo(x: Int, y: Int): Int = x + y
foo: (Int,Int)Int
스칼라 타입 추론 (모든 타입을 써준 경우)
하지만 동적 타이핑하는 언어와 달리 모든 타입을 생략하면 컴파일러가 타입을 추론할 없기 때문에 오류가 발생한다. 스칼라 코딩을 처음 시작한 사람들은 타입을 어느 정도 생략해도 되는지 알기 어려운데, 시행착오를 통해 컴파일러가 어디까지 타입 추론을 해주는지 감을 잡는 일이 필요하다. 단, 컴파일러가 추론할 수 있더라도 필요한 경우에는 적절히 타입을 써주면 코드의 가독성을 높일 수 있음을 명심하자.
scala> def foo(x, y) = x + y
<console>:1: error: ':' expected but ',' found.
def foo(x, y) = x + y
^
<console>:1: error: identifier expected but eof found.
def foo(x, y) = x + y
^
스칼라 타입 추론 (실패)
선언(val/var/def)
스칼라는 변수를 선언할 때 자바처럼 모든 타입을 다 적어줄 필요가 없다. 변수 x를 선언하고 1을 넣어주려면 다음과 같이 var 키워드를 사용하면 된다. var은 자바 변수와 동일하다.
scala> var x = 1
x: Int = 1
scala> x = x + 1
x: Int = 2
var의 사용
스칼라는 var 외에도 val을 통해 값을 선언할 수 있는데, val은 var로 선언된 변수와 달리 값이 변하지 않는다. val로 만든 x에 x + 1이라는 새로운 값을 집어넣으면 다음처럼 x는 변경 불가능한 값(immutable value)이라는 오류가 발생한다.
scala> val x = 1
x: Int = 1
scala> x = x + 1
<console>:7: error: assignment to immutable value
x = x + 1
^
val의 사용
스칼라에는 var/val 외에도 함수 객체를 선언하는 데 사용하는 def 키워드가 있다. def는 다음처럼 val과 마찬가지로 변하지 않는 값을 선언하는 데 사용할 수 있다.
scala> def x = 1
x: Int
scala> x = x + 1
<console>:7: error: value x_= is not a member of object $iw
x = x + 1
^
def의 사용
val과 def의 차이는 연산을 하는 시점에 있다. val은 val을 선언하는 시점에 우변을 계산해서 값을 할당하는 반면에 def는 실제로 사용되는 시점마다 우변을 새로 계산한다. 다음 예제는 이 차이를 분명하게 보여준다.
scala> var x = 1
x: Int = 1
scala> val y = x + 1
y: Int = 2
scala> def z = x + 1
z: Int
scala> z
res13: Int = 2
scala> x = 2
x: Int = 2
scala> y
res15: Int = 2
scala> z
res16: Int = 3
var과 def의 차이
위 예제에서 var로 선언한 변수 x에 1을 넣은 다음에 y와 z 모두 x + 1로 정의해주었다. 다만 y는 val을 z는 def를 사용해서 선언하였다. 일단 val y는 선언하는 순간에 값이 2임을 표시해준 반면에 def z를 선언했을 때는 타입이 Int라는 사실만 알려주고 값을 계산하지 않았음을 알 수 있다. z를 실제로 사용했을 때 2로 계산해준다. 이후 변수 x의 값을 2로 변경했을 때, y는 이미 선언한 시점에서 계산이 끝났으므로 값이 변경되지 않고 여전히 2인 반면에 z는 다시 x + 1을 이 시점에서 새로 계산하기 때문에 x 값을 2로 계산해서 3을 돌려줌을 볼 수 있다.
클래스
스칼라의 클래스는 기본적으로 자바와 유사하다. 다만 별도의 생성자 없이 클래스 이름 옆에 객체 생성 시 어떤 인자를 받을 것인지 써준다는 차이가 있다. 아래 Person 클래스는 성과 이름을 입력받는 간단한 클래스이다.
class Person(fname: String, lname: String) {
def firstname() = fname
def lastname() = lname
override def toString() = firstname() + " " + lastname()
}
스칼라 클래스의 예
toString 메서드는 java.lang.Object의 toString 메서드를 오버라이드(override)한 것이다. 스칼라는 상위 클래스의 메서드를 오버라이드할 때 명시적으로 override라는 키워드를 써줘야 한다. 실수로 상위 클래스의 메서드를 의도치 않게 오버라이드하는 것을 막기 위한 조치이다.
케이스 클래스(case class)와 패턴 매칭(pattern matching)
패턴 매칭은 함수 언어의 고유한 특징 중에 하나로 함수 언어를 강력하게 만들어주는 핵심이다. 스칼라는 케이스 클래스를 통해 객체지향 언어 속에 패턴 매칭을 녹여 넣었다.
abstract class Shape
case class Rectangle(width: Double, height: Double) extends Shape
case class Circle(radius: Double) extends Shape
case class Square(side: Double) extends Shape
케이스 클래스의 예
케이스 클래스는 일반 클래스와 달리 다음과 같은 몇 가지 특징을 갖는다.
(1) 새로운 객체를 생성하기 위해 new 키워드를 사용할 필요가 없다. new Circle(5.0) 대신에 Circle(5.0)이라고 사용할 수 있다.
(2) 생성자의 파라미터에 사용된 값을 얻을 수 있는 getter 메서드가 자동으로 생성된다. 예를 들어 var c = Circle(5.0)를 선언했다면 c.radius는 5.0을 리턴한다.
(3) equals와 hashCode 메서드가 자동으로 만들어진다.
(4) toString 메서드가 자동으로 정의된다. Rectangle(5.0, 3.0)을 출력해보면 "Rectangle(5.0, 3.0)"이 나온다.
(5) 패턴 매칭을 통해 분해(decompose)될 수 있다.
케이스 클래스의 최대 장점은 (5)에서 언급한 패턴 매칭의 사용이다. 다음은 패턴 매칭을 사용한 면적(area) 계산 함수이다.
def area(s: Shape): Double = s match {
case Rectangle(width, height) => width * height
case Circle(radius) => radius * radius * 3.14
case Square(side) => side * side
case _ => 0
}
def perimeter(s: Shape): Double = s match {
case Rectangle(width, height) => 2 * (width + height)
case Circle(radius) => 2 * 3.14 * radius
case Square(side) => side * 4
case _ => 0
}
패턴 매칭을 통한 Shape의 면적/둘레 계산
area(면적)와 perimeter(둘레) 함수는 Shape의 객체 s를 넘겨받아 패턴 매칭을 한다. s의 객체가 Rectangle, Circle, Square일 때 각각의 케이스에 대해 어떤 일을 수행할 것인지 적어주면 된다. 이때 각 객체를 만들 때 사용되었던 인자가 원하는 변수에 자동으로 매칭된다. 예를 들어, Rectangle(5.0, 3.0)을 s로 넘겼다면 첫 번째 케이스에서 width와 height는 각각 5.0, 3.0이 된다. _는 앞선 패턴 매칭이 모두 실패했을 때 디폴트로 호출되는 케이스를 의미한다.
객체지향 프로그래밍에 익숙한 개발자라면 area를 Shape의 메서드로 선언하고, Rectangle, Circle, Square 등 각각의 서브클래스가 area를 구현하는 방식으로 코드를 작성할 수도 있을 것이다. area나 perimeter 같은 메서드는 몇 개로 고정되어 있고, Triangle이나 Ellipse 등 새로운 Shape이 계속 추가되는 상황이라는 이 방법이 더 좋다. 새로 추가되는 Shape에서 area와 perimeter 등 몇 개의 메서드만 구현해주면 되고 기존 파일을 고칠 필요가 없기 때문이다.
반대로 Shape의 종류는 고정된 상황에서 area, perimeter 등의 메서드를 계속 추가해 나가야 되면 상황이 달라진다. 메서드가 하나 추가될 때마다 모든 Shape의 서브클래스를 찾아서 메서드를 추가해줘야 하기 때문이다. 자바를 비롯한 전통적인 객체지향 언어에서는 이 문제를 비지터 패턴(visitor pattern)을 이용한 더블 디스패치(double dispatch)로 풀었다. 하지만 비지터 패턴은 이해하기도 어렵고, 싱글 디스패치하는 일반적인 객체지향 언어에서 자연스러운 접근 방법도 아니다.
패턴 매칭은 이런 상황에서 완벽한 솔루션을 제공한다. 새로운 함수/메서드를 만들고 패턴 매칭을 통해 각각의 케이스를 다루면 되기 때문이다. 케이스 클래스라고 이름 붙인 이유는 이처럼 패턴 매칭을 통해 각 케이스를 다룬다는 면을 강조한 것이다.
제네리시티(Genericity)
마지막으로 살펴볼 내용은 자바 제네릭스에 대응하는 제네리시티이다. 스칼라의 제네리시티는 자바보다 문법적으로 훨씬 간결하고 직관적이다. 이해를 위해 스칼라 튜토리얼에 있는 예제 코드를 하나 살펴보자.
class Reference[a] {
private var contents: a = _
def set(value: a) { contents = value }
def get: a = contents
}
제네리시티
아무 타입이나 저장할 수 있는 Reference 클래스를 만들기 위해서 [a]라는 타입 파라미터를 받았다. Reference의 contents 필드를 타입 a로 선언했고, get의 리턴 타입과 set의 value 타입을 a로 선언했다. 실제로 사용할 때는 val cell = new Reference[Int] 형태로 타입을 넘겨주면 된다. 참고로, 스칼라는 기본 타입과 레퍼런스 타입의 구분이 없기 때문에 Int를 넣기 위해 Integer 객체를 만들어 박싱할 필요가 없다.
정리
스칼라는 다른 함수 언어와 달리 JVM 위에서 동작하는 언어라는 이점 때문에 상당히 실용적이다. 특히 이미 기존 자바 개발자들에게 스칼라는 기존 프로젝트 플랫폼을 변경하지 않고 필요한 부분에서 생산성을 높일 수 있는 중요한 도구가 될 것이다.
스칼라 컴파일러와 런타임의 버전은 2.7.0으로 상당히 안정되어 있고, 지금은 스칼라를 기반으로 한 라이브러리와 프레임워크도 출연하기 시작했다. Lift는 스칼라를 이용한 웹 프레임워크이고, Scalax, Scalaz 프로젝트 등은 스칼라 라이브러리이다. 또한 멀티 코어 시대를 대비한 병렬 프로그래밍(얼랭(Erlang)과 유사한 프로세스 모델을 제공) 또한 스칼라가 자랑하는 기능 중 하나이다.
짧은 지면에 새로운 프로그래밍 언어를 처음부터 소개하려다보니 응용 부분에서 많은 내용이 빠졌다. 보다 자세한 내용은 스칼라 홈페이지(http://www.scala-lang.org/)를 통해 얻길 바란다.
Scalax, Scalaz
스칼라는 JDK에 있는 클래스들을 쉽게 사용할 수 있지만, 한편으로는 스칼라 프로그래밍 언어 자체의 특징을 살리기 위한 라이브러리의 개발도 한참이다. 대표적으로 Scalax와 Scalaz 프로젝트가 있다.
일례로 Scalaz는 ScalaCheck이라는 테스팅 프레임워크를 제공한다. 물론 스칼라도 자바 테스팅 프레임워크인 JUnit을 사용할 수 있지만, ScalaCheck은 JUnit과 달리 함수 언어의 특징을 살려 명세 기반의 자동화된 테스팅을 제공한다. 이는 헤스켈의 QuickCheck과 유사하다. 또한 Scalaz는 함수 언어의 특징을 살리고자 모나드(monad) 관련 패키지도 제공한다.
스칼라의 장점을 잘 살린 함수형 프로그래밍을 하고 싶다면 이런 라이브러리 프로젝트가 중요한 학습 소스가 될 것이다.
참고문헌
[1] A Scala Tutorial for Java Programmers
http://www.scala-lang.org/docu/files/ScalaTutorial.pdf
[2] Scala by Example
http://www.scala-lang.org/docu/files/ScalaByExample.pdf
[3] An Overview of the Scala Programming Language
http://www.scala-lang.org/docu/files/ScalaOverview.pdf
[4] The Scala Language Specification Version 2.7
http://www.scala-lang.org/docu/files/ScalaReference.pdf
- Filed under : 카테고리 없음
