코드 난독화(Code Obfuscation)
Posted 2008. 11. 30. 01:04마이크로소프트웨어 2007년 12월에 기고한 글입니다.
요즘 보안 취약점 분석자들은 각종 보안 문제 분석에 역공학(reverse engineering) 기술을 적극 활용하고 있다. 역공학은 소스 코드 없이 윈도우즈 실행 파일(PE, Portable Executable)이나, 자바 바이트코드 등을 직접 분석해서 프로그램이 어떤 기능을 수행하는지 파악하여 취약점을 찾아내는 기술이다, 필요하면 직접 프로그램 바이너리를 수정해 불법적인 일을 수행하게 만들기도 한다. 이에 대한 대응으로 코드를 복잡하게 만들어 알아보기 힘들게 하는 코드 난독화(code obfuscation) 기술이 발전하였다. 이 글에서는 코드 난독화의 기본 원리를 알아보자.
역공학(reverse engineering)이란?
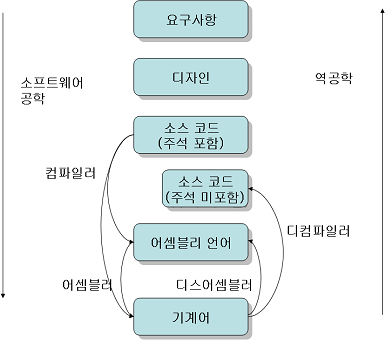
역공학의 개념
대부분의 개발자들은 컴파일된 바이너리를 완전한 블랙박스로 취급한다. 윈도의 PE 포맷이나 리눅스의 ELF 포맷을 이해하더라도 코드섹션(code section)에 들어있는 기계어(어셈블리어)를 이해하기란 무척 어렵다. 하지만 보안 취약점 분석가들의 주요 업무는 이런 바이너리 코드를 읽고 보안 취약점을 찾아내는 것이다. 이는 보안 전문가들이라 할지라도 쉽지 않은 일인데, 보통 컴파일된 바이너리를 다시 원래의 소스코드로 복구하는 프로그램인 디컴파일러(decompiler)의 도움을 받는다. 디컴파일러는 원래 소스 코드를 완벽히 복구하지는 못하지만, 어셈블리에 비해서는 훨씬 이해하기 쉬운 프로그래밍 언어(주로 C)의 소스 코드를 생성해준다. 또한 코드 섹션에 직접 브레이크를 걸고 실행시켜볼 수 있는 디버거(debugger)의 도움을 받는 경우도 많다.
이처럼 바이너리 코드를 분석해 유용한 정보를 뽑아내는 작업을 역공학(reverse engineering)이라 부른다. 최근 보안 취약점 분석의 상당 부분은 역공학과 관련되어 있다. 실제로 역공학은 윈도우처럼 소스 코드가 공개되지 않은 운영체제나, 어플리케이션의 보안 버그를 찾아내는데 적극적으로 활용되고 있다.
역공학의 위험성을 보여주는 예로, 각종 보안 프로그램들이 뚫린 사례를 들 수 있다. 예를 들어 도서관 같은 공용 컴퓨터에 불법적인 프로그램을 설치하는 것을 막기 위해 리부팅하면 하드가 리셋(reset)되는 시스템이 있다. 이 시스템은 추가적은 프로그램 설치를 위해 관리자 모드를 제공하는데, 4자리의 패스워드를 입력하도록 되어있다. 역공학을 이용해 패스워드를 검사하는 루틴을 찾아내면, 이 부분을 건너뛰게 만들 수도 있다.
수십 가지의 안전장치를 마련한 인터넷 뱅킹도 예외가 아니다. 안전한 공인 인증서를 이용한다고 해도, 입력받은 비밀번호와 공인인증서 비밀번호를 비교하는 코드를 찾아내서 해당 루틴을 건너뛰게 만든다면 공인인증서의 비밀번호(passphrase)는 의미가 없어진다. 아무리 많은 안전장치를 걸어놔도 윈도 머신에서 실행되는 바이너리라면, 그 내용을 분석해 해당 코드를 제거해 버리면 되기 때문이다.
현재 MS 윈도의 보안 모델에서는 이런 역공학에 의한 공격에 효과적인 대응책이 없다. 그나마 우리가 할 수 있는 차선책은 바이너리를 분석하기 어렵도록 복잡하게 만들어 주는 것이다. 코드 난독화의 필요성은 여기서 출발한다.
코드 난독화(code obfuscation)
코드 난독화는 프로그램을 변화하는 방법의 일종으로, 코드를 읽기 어렵게 만들어 역공학을 통한 공격을 막는 기술을 의미한다. 난독화는 난독화의 대상에 따라 크게 1) 소스 코드 난독화와 2) 바이너리 난독화로 나눌 수 있다. 소스 코드 난독화는 C/C++/자바 등의 프로그램의 소스 코드를 알아보기 힘든 형태로 바꾸는 기술이고, 바이너리 난독화는 컴파일 후에 생성된 바이너리를 역공학을 통해 분석하기 힘들게 변조하는 기술이다.
일단 소스 코드 난독화의 필요성을 먼저 이야기해보자. 첫 번째 경우는 부득이하게 소스 코드를 릴리즈(release)해야 하는 경우이다. 예를 들어 플래시 파일 시스템을 파는 A라는 회사가 있다고 하자. B 회사는 A 회사의 라이브러리를 구매해서 제품을 만들려고 한다. B 회사는 매우 많은 플랫폼을 가지고 있고, 여러 설정에 따라서 플래시 파일 시스템을 조금씩 다르게 컴파일해야할 필요가 있다고 하자. 이 경우 B 사가 일일이 해당 라이브러리를 빌드해서 릴리즈해주는 방법도 있지만, 난독화 도구를 이용해 코드를 적당히 알아보기 힘들게 만든 후에 A 사에 넘겨서 A사가 직접 빌드하도록 하는 것이 편리할 것이다.
또 다른 예로 최근 부각 받는 AJAX의 경우, 자바스크립트(JavaScript)로 작성된 코드가 브라우저에 그대로 노출되는 문제가 있다. 소스 코드를 공개하고 싶지 않은 개발자라면 AJAX의 이런 특성이 큰 부담이 될 것이다. 이 경우 자바스크립트 코드를 쉽게 알아보지 못하도록 난독화 도구를 사용할 수 있다. 다음은 JavaScript Obfuscator가 실제로 자바 스크립트를 난독화한 예제이다. 원래 코드와 난독화된 코드를 비교해보면, 난독화 과정에 대한 감을 잡을 수 있을 것이다.
<원래 코드>
//detect which browser is used
var detect = navigator.userAgent.toLowerCase();
var OS,browser,version,total,thestring;
if (checkIt('konqueror'))
{
browser = "Konqueror";
OS = "Linux";
}
else if (checkIt('opera')) browser = "Opera"
else if (checkIt('msie')) browser = "Internet Explorer"
else if (!checkIt('compatible'))
{
browser = "Netscape Navigator"
version = detect.charAt(8);
}
else browser = "An unknown browser";
//version of browser
if (!version) version = detect.charAt(place + thestring.length);
//client OS
if (!OS)
{
if (checkIt('linux')) OS = "Linux";
else if (checkIt('x11')) OS = "Unix";
else if (checkIt('mac')) OS = "Mac"
else if (checkIt('win')) OS = "Windows"
else OS = "an unknown operating system";
}
//check the string
function checkIt(string)
{
place = detect.indexOf(string) + 1;
thestring = string;
return place;
}
<난독화된 코드>
C/C++ 개발자에게는 코드 난독화가 생소한 개념일 수 있지만, 자바 개발자들은 수년전부터 코드 난독화 도구를 실용적인 목적으로 이용해 오고 있다. 자바의 바이트코드는 윈도 실행 파일보다 훨씬 많은 심볼(symbol)을 컨스턴트 풀(constant pool) 영역에 가지고 있기 때문이다. 난독화를 거치지 않은 자바 바이트코드를 디컴파일해보면, 원래 소스 코드의 대부분이 복구되는 것을 알 수 있다.
코드 난독화에 대한 재미난 사실은 이 기술이 바이러스나 웜 제작자들에 의해 처음 연구되었다는 사실이다. 바이러스나 웜은 백신의 스캔에 걸리지 않기 위해 자신의 바이너리를 교묘한 형태로 숨겨왔는데, 이렇게 바이너리를 변형해 정보를 숨기는 기술이 바이너리 코드 난독화의 목표이다. 반면에 백신 개발자들은 이렇게 변형된 웜을 탐지하기 위해, 소스 코드를 확인할 수 없는 바이너리 코드의 안정성과 취약점을 분석하는 기술을 발전시켜왔다, 코드 난독화와 바이너리 분석 기술은 서로 경쟁하는 기술인 셈이다.
기본적인 바이너리 코드 난독화 방법
가장 기본적인 코드 난독화는 바이너리에서 심볼 정보를 제거하거나 변경하는 것이다. C/C++로 컴파일된 바이너리의 경우 디버깅 옵션을 주면 바이너리에 심볼 정보가 포함되는데 난독화 도구는 이런 정보를 지워서, 바이너리에서 사람이 이해할 수 있는 정보를 최대한 제거하는 것이다. 자바의 경우는 심볼 정보가 프로그램 수행에 필요하므로, 심볼 정보를 제거할 수는 없다. 대신에 자바용 난독화 도구는 심볼 이름을 바꾸는 방법을 많이 사용한다. MyString이라는 클래스 이름보다는 M라는 클래스 이름이 알아보기 어렵고, find라는 메쏘드 이름보다는 f라는 이름이 공격자가 이해하기 어렵다는 점에 착안한 것이다.
그 외에도 다음과 같은 난독화 방법이 있다.
1. 필요 이상으로 복잡한 코드를 만들거나, 아무 것도 하지 않는 코드를 삽입한다.
이 난독화 기술은 실행되지 않는 함수를 추가하거나, 아무 것도 하지 않는 함수들을 중간 중간에 삽입하여 바이너리 코드 분석을 힘들게 만드는 것이다. 이런 일은 데드 코드(dead code)를 제거하고, 코드를 짧고 간단하게 만드는 최적화 컴파일러(optimizing compiler)가 하는 일에 역행하지만, 역공학을 어렵게 만드는 데는 효과적이다.
물론 이런 기술을 사용해도 공격자가 함수 호출 그래프(call graph)와 흐름 그래프(control flow graph)를 그리고, 세심하게 코드를 분석하면 취약점을 찾아내는 것은 시간문제이다. 하지만 그렇다고 이런 난독화 기술이 의미가 없지는 않다. 난독화의 목표는 역공학을 불가능하게 만드는 게 아니라, 충분히 어렵게 만들어서 공격자가 포기하고 다른 공격 대상을 찾게 만드는 데 있기 때문이다.
2. 코드를 여기저기로 복사하고, 옮긴다.
관련된 코드를 최대한 멀리 떨어진 곳에 배치하거나, 함수를 인라이닝(inlining)하고, 반복되는 몇 개의 구문(statement)을 합쳐서 익명의 함수를 만드는 등의 일을 할 수 있다. 똑같은 함수를 복사하여, 각기 다른 지점에서 다른 함수 이름을 사용하는 방법도 있다. 연달아 불리는 서로 관련 없는 함수를 하나의 함수로 묶어주는 방법도 있다. 성능을 심각하게 해치지 않는 범위에서 코드를 뒤섞는 모든 방법이 여기에 포함된다.
3. 데이터를 알아보기 힘들게 인코딩(encoding)한다.
취약점 분석가들이 바이너리 분석에서 가장 먼저 하는 일은 바이너리에 포함된 텍스트(text) 문자열을 찾아내는 것이다. 일례로, C 언어로 char passwd[] = "mypass"; 같은 코드가 컴파일되어 바이너리에 포함되어 있다면 strings 명령으로 바이너리를 스캔해 보는 것만으로도 암호를 발견해 낼 수 있다. 믿지 않겠지만, 실제로 이런 코드가 발견되는 경우가 매우 빈번하다.
해결책은 텍스트 문자열을 알아보기 힘든 방식으로 인코딩하고 필요할 경우만 디코딩(decoding)해서 사용하는 방법이다. 특히 외부로 노출되었을 경우 곤란한 정보인 경우, 이런 과정을 거치는 것이 좋다. 인코딩/디코딩하는 방법으로 암호 알고리즘을 사용하는 것도 한 방법이다. 하지만 암호 알고리즘도 역공학 앞에서는 완벽한 보호책이 되지 못한다. 복호화에 사용되는 키가 메모리 어딘가에 반드시 존재해야 하고, 복호화 직전에 이 키를 읽어와야만 하기 때문이다. 공격자는 언제든지 암호키를 읽을 수 있다.
앞서 살펴본 3가지 방법은 역공학을 어렵게 만들기는 하지만, 프로그램의 성능을 심각하게 떨어뜨릴 수 있다. 난독화 도구는 각종 난독화 방법을 적용할지 여부를 옵션으로 남겨놓는데, 시스템과 성능과 역공학에 대한 저항성 등을 상충되는 요구 사항을 잘 고려한 후에 결정해야할 문제다.
정리
앞서 이야기한 것처럼 역공학에 대한 100% 완벽한 대안은 없다. 바이너리를 분석하고 수정할 수 있다면 어떠한 안전장치도 통과할 수 있기 때문이다. 다만 전자 상거래나 보안 제품 등 높은 수준의 보안성을 요구하는 프로그램이라면, 약간의 성능 저하를 감수하고서라도 각종 코드 난독화 기술을 적용해볼 여지를 가지고 있다.
이 글에서는 역공학과 코드 난독화의 기본적인 개념과 간단한 메커니즘만 소개하였고, 세부적인 기술에 대한 논의는 지면 관계상 보류하였다. 관심 있는 독자는 "obfuscate"라는 단어로 좀 더 많은 자료를 찾아보길 바란다.
참고 문헌
[1] Building Secure Software, Viega, McGraw, Addison-Wesley
- Filed under : 카테고리 없음
