소프트웨어 트랜잭션 메모리(STM)와 하스켈
Posted 2008. 11. 29. 04:12
2008년 4월 마이크로소프트웨어 기고글입니다.
병렬 프로그래밍
병렬 프로그래밍(parallel programming)은 하나의 프로그램이 동시에 여러 일을 수행하게 만드는 방법을 통칭한다. 병렬 프로그래밍이라는 말은 고성능 컴퓨팅(HPC, High Performance Computing)의 한 분야를 지칭하는 좁은 뜻으로도 사용되기 때문에 혼돈을 피하기 위해 동시 프로그래밍(concurrent programming)이라는 말을 쓰기도 한다.
병렬 프로그래밍의 가장 일반적인 사례는 자원(보통은 메모리)을 공유하고 락(lock)과 컨디션 변수(conditional variable) 통해 공유 자원의 접근을 통제하는 멀티쓰레드 프로그래밍이다. OS 프로세스를 여러 개 만들고 프로세스 간 통신(IPC, Inter-Process Communication)을 통해 데이터를 처리하는 것도 병렬 프로그래밍의 한 예이다. 함수형 언어인 얼랑(Erlang)처럼 여러 프로세스(process, 여기서 프로세스는 OS 프로세스가 아닌 언어 런타임의 경량 프로세스임)가 메시지 큐(message queue)를 통해 데이터를 주고받는 모델도 병렬 프로그래밍의 한 예이다.
병렬 프로그램을 작성하는 일은 순차적인 프로그램 작성에 비해 무척 어렵다. 일례로 데이터 구조의 일종인 데크(double ended queue)를 작성하는 일은 학부생 프로그래밍 숙제 수준에서 해낼 수 있는 일이지만, 규모가변성(scalability) 보장되면서 쓰레드-세이프(thread-safe)한 데크 작성은 논문으로 낼 수 있는 수준이 된다.
여기서 규모가변성이란 코어의 수를 늘렸을 때 프로그램의 성능 향상이 일어나는 정도를 말한다. 코어가 2배가 되었을 때 프로그램 성능이 2배가 된다면 규모가변성이 매우 뛰어난 병렬 프로그래밍이고, 코어가 2배가 되었음에도 성능 향상이 미미하다면 규모가변성이 떨어지는 프로그램이다.
락/컨디션 변수의 문제점
병렬 프로그래밍의 고전이자 가장 일반적인 모델은 락과 컨디션 변수를 이용한 멀티쓰레드 프로그래밍이다. 멀티쓰레드 프로그래밍은 공유 자원(혹은 공유 메모리)을 가정하고 여러 개의 쓰레드가 동시에 프로그램을 수행하며 같은 자원에 데이터를 읽고 쓰며 통신하는 방법이다. 락과 컨디션 변수는 운영체제를 비롯해 일부 시스템 소프트웨어를 작성하는데 주로 사용되었으나, 자바가 모니터(락과 컨디션 변수)를 프로그래밍 언어에 포함시키면서 일반 개발자들도 널리 사용하게 되었다.
하지만 결론부터 이야기하면 락을 이용한 멀티쓰레드 프로그래밍 기술이 널리 퍼질수록 전 세계의 개발자들은 더욱 더 많은 버그를 만들어내고 인터넷으로 연결된 우리가 사는 이 세상은 더 나빠진다. 멀티쓰레드 프로그램을 오류 없이 설계하기는 어렵기 때문이다. 또한 비결정적인(nondeterministic)인 프로그램 특성 때문에 테스트가 어렵고, 버그가 발생해도 재현이 힘들기 때문에 멀티쓰레드 프로그램의 디버깅은 불가능에 가깝다.
락을 이용한 멀티쓰레드 프로그래밍의 결정적 문제는 안정성과 규모가변성의 충돌이다. 멀티쓰레드 프로그램을 정확하고 안전하게 짜는 방법은 락을 최대한 적게 쓰는 데 있다. 동기화가 필요한 부분에 큰 단위로 락을 잡으면 복잡도가 낮아서 비교적 정확한 프로그램을 짤 수 있다. 하지만 동기화 단위가 큰 만큼 많은 쓰레드가 유용한 일을 수행하기 보다는 다른 쓰레드가 작업 수행을 끝내기를 기다리면서 대부분의 시간을 보내게 된다. 즉, 코어가 2배 4배가 되더라도 성능 향상은 미미할 가능성이 크다. 반대로 락을 잘게 쪼개서 잡으면 규모 가변성이 좋아지지만 데드락(deadlock)과 레이스 컨디션(race condition)이라는 고질적인 병폐에 부딪힐 확률이 그만큼 커진다. 빠르기만 하고 계산 값이 틀린 엉터리 프로그램이 되는 셈이다.
락의 문제점을 정리하면 다음과 같다.
1) 레이스: 락 잡는 것 잊어먹었을 때 발생한다.
2) 데드락: 락을 정해진 순서와 다르게 획득했을 때 발생한다.
3) 깨어나지 않음: 컨디션 변수를 깨우지(wakeup) 않았을 때 발생한다.
4) 에러 복구: 에러가 발생했을 때 락을 모두 해제하지 못했을 때 발생한다.
STM이란?
멀티쓰레드 프로그래밍의 병폐는 이미 널리 알려져 있고 이미 수많은 글들이 이런 문제를 극복하는 방법을 다루고 있다. 일례로 데드락을 방지하기 위해서는 시스템의 존재하는 모든 락에 순서를 매기고, 여러 개의 락을 획득할 때는 반드시 정해진 순서를 따르는 것이 한 방법이다. 불필요한 공유 자원 사용을 줄이고 블로킹 큐(blocking queue), 카운트다운 래치(countdown latch) 등 고수준의 유틸리티 클래스를 사용하는 것도 대책이 될 수 있다.
이 글에서는 락 기반 멀티쓰레드 프로그래밍의 팁 대신 멀티코어 시대에 새로운 병렬 프로그래밍 모델로 주목받고 있는 소프트웨어 트랜잭션 메모리(이하 STM)를 소개하려 한다.
STM은 데이터베이스에서 말하는 트랜잭션(transaction)의 개념을 프로그래밍 언어로 빌려온 것이다. DB 트랜잭션과 마찬가지로 프로그램 내에서 하나의 단위로 수행되어야 하는 일을 묶어주고 그 일을 모두 수행하거나 전혀 수행하지 않는다. 쉽게 말해서 모 아니면 도(all or nothing) 방식이다. STM에서는 중간 상태(inconsistent state)가 노출되는 문제가 존재하지 않는다.
이해를 돕기 위해 병렬 프로그래밍의 고전적인 예인 은행 계좌 이체를 생각해보자 계좌 A에서 돈을 빼내서 계좌 B로 이체하기 위해서는 2가지 일을 해야 한다. 1) 일단 A 계좌에서 돈을 인출하고 2) B 계좌에 돈을 넣는다. (물론 2번, 1번순으로 처리할 수도 있다.) 데이터베이스에서는 이런 상황을 ACID 모델로 해결한다. ACID의 A는 원자성(atomicity)로 1, 2는 하나의 단위로 수행되어야 함을 뜻한다. I는 독립성(isolation)으로 도중에 다른 태스크에 의해 방해받지 않음을 뜻한다. C(consistency)와 D(durability)는 저장 매체와 관련이 있다.
STM에 대한 이해를 돕기 위해 하스켈로 작성된 프로그램을 하나 살펴보자. 아래 하스켈 코드는 계좌 from에서 계좌 to로 amount만큼의 돈을 이체하는 간단한 함수이다. ***참고로 대부분의 개발자에게는 낯선 하스켈을 선택한 이유는 하스켈이 STM을 가장 먼저 시작한 프로그래밍 언어이고 하스켈의 강력한 타입 시스템이 STM의 장점을 잘 살려주기 때문이다.
transfer :: Account -> Account -> Int -> IO ()
-- 은행 계좌 'from'에서 'to‘로 amount만큼 이체한다.
transfer from to amount
= atomically ( do { deposit to amount
; withdraw from amount } )
하스켈로 작성된 은행계좌 이체
일단 transfer :: Account -> Account -> Int -> IO ()로 표기된 부분은 transfer 함수의 타입을 선언한다. 각각의 인자는 -> 로 구분되어 있는데, transfer 함수는 첫 번째 인자와 두 번째 인자로 Account 타입을 받고, 세 번째 인자로는 Int(정수)를 받는다. 마지막 IO ()는 transfer 함수의 리턴 타입을 나타내는데 IO를 수행하고 ()를 리턴함을 의미한다. 참고로 ()는 C/C++, 자바의 void와 동일하게 리턴 값이 없을 때 사용한다.
다음은 실제로 함수를 정의하는 부분이다. transfer 함수는 from to amount라는 세 개의 인자를 받으며 amount 만큼을 to 계좌에 입금하고, amount 만큼을 from 계좌에서 인출한다. deposit to amount는 deposit이라는 함수를 to와 amount 2개의 인자로 호출한 함수 호출이다. do 명령은 하스켈에서 IO를 수행하기 위한 블록(반드시 IO만은 아니고 모나드에 적용된다.)으로 do {} 안에 명령은 순차적으로 실행된다. 따라서 일단 to 계좌에서 돈을 인출한 다음에 from 계좌에 돈을 넣게 되는 것이다.
여기서 주목할 부분은 atomically이다. do 블록을 감싸고 있는 atomically는 앞서 언급한 원자성(atomicity)과 독립성(isolation)을 보장해준다. atomically 안에 들어있는 STM 액션은 기본적으로 모 아니면 도 스타일로 중간 상태를 허용하지 않는다.
이 방식의 장점은 다음과 같다.
1) 락을 획득하는 순서 때문에 발생하는 데드락 문제가 사라진다.
2) 또한 에러 발생 시 복구도 자동으로 이루어진다.
3) 규모가변성 측면에서 뛰어나다. 아래 그래프는 사이먼 페이튼 존스(Simon Peyton Jones)가 2007년 OSCON에서 발표한 규모가변성 자료이다. 컴파일러와 통합한 STM의 경우 성능이 인상적이다.
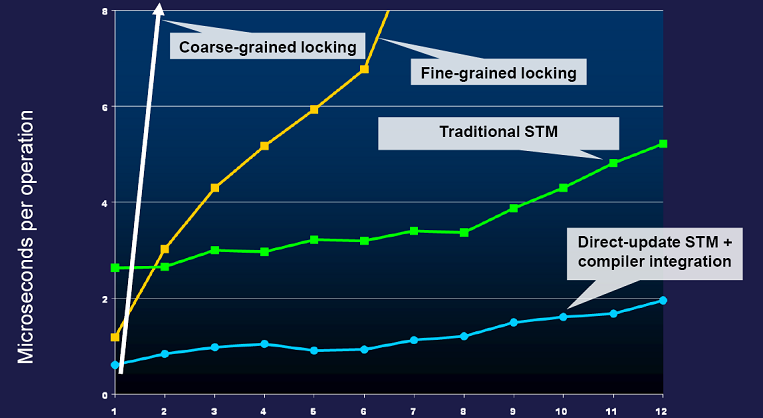
하지만 다음 2가지 문제는 여전히 남아 있는 것처럼 보인다.
1) 명시적으로 락을 잡는 것에 비해 성능 향상이 없다.
사실이 아니다. 이 문제는 atomically를 어떻게 구현하느냐에 달려있다. 일반적으로 STM이 취하는 방식은 DB 트랜잭션이 주로 사용하는 낙관적 동시성(optimistic concurrency) 방식과 동일하다. 하스켈에서 atomically 지정된 STM 액션은 아무런 락을 잡지 않고 일단 코드를 수행한다. 코드 수행 도중에 발생하는 메모리 읽기/쓰기는 트랜잭션 로그에 남긴다. 메모리 쓰기는 메모리에 직접 수행하지 않고 로그에만 남긴다. atomically가 끝나면 트랜잭션 로그를 한 번에 커밋한다. 만약 그 사이에 다른 쓰레드가 들어와서 트랜잭션이 읽고 쓴 메모리를 변경했다면, 트랜잭션을 다시 수행한다.
2) atomically를 선언하지 않고 같은 메모리에 접근하는 경우가 생기면 레이스 컨디션의 문제가 있다.
이 문제는 락 기반 멀티쓰레드 프로그램의 고질적인 문제점이다. 락은 기본적으로 모든 참여자가 룰을 지킬 것이라는 믿음 하에 출발한다. 특정 메모리 영역에 접근하기 위해서는 특정 락을 잡겠다는 규칙을 모두가 지켜야만 레이스 컨디션이 없는 프로그램을 작성할 수 있다. 단 하나라도 이 규칙을 깨뜨리는 경우가 생기면 그대로 버그가 되기 때문이다.
얼핏 보면 atomically도 같은 문제점을 안고 있는 것처럼 보인다. 하나라도 atomically를 사용하지 않고 메모리에 접근하면 레이스 컨디션이 생기기 때문이다. 하스켈은 이 문제를 타입 시스템을 통해 풀었다. atomically는 얼핏 보기에 프로그래밍 언어의 고유 기능으로 보이지만 실제로는 다음 타입을 갖는 함수이다.
atomically의 타입
STM 액션은 IO 액션과 마찬가지로 사이드 이펙트를 가지지만 그 범위가 훨씬 좁다. STM 액션에서 할 수 있는 일은 (TVar a) 타입의 트랜잭션 변수를 읽고 쓰는 것만 가능하다. 반대로 IO 액션에서는 IO 변수만 읽고 쓸 수 있으며 직접 트랜잭션 변수에 접근하지 못한다. IO 액션에서 트랜잭션 변수에 접근하는 유일한 방법이 atomically이다. atomically를 사용하지 않고는 트랜잭션 변수에 접근할 수 없게 타입 시스템에서 강제한 것이다.
STM 액션
앞서 atomically로 지정된 STM 액션들은 자동으로 원자성과 독립성을 보장받는다고 말했다. 이제는 실제로 STM 변수를 어떻게 사용하는지 살펴보자.
type Account = TVar Int
withdraw :: Account -> Int -> STM()
withdraw acc amount
= do { bal <- readTVar acc
;writeTVar acc (bal - amount) }
withdraw 함수
위 예제는 withdraw 함수를 STM을 통해 구현한 것이다. STM 변수는 TVar(TArray, TChan, TMVar 등도 있다) 타입으로 위 예제에서는 Account를 TVar Int로 정의했다. STM 변수는 2가지 기능이 있다. readTVar는 변수의 값을 읽는 것이고, writeTVar는 변수의 값을 쓴다. 앞서 말한 것처럼 이때 STM 액션은 공유 메모리에 쓰기 전에 임시로 다른 장소에 저장을 했다가 다른 태스크의 방해 없이 수행에 성공하면 한 번에 커밋한다.
deposit :: Account -> Int -> STM()
deposit acc amount = withdraw acc ( - amount)
deposit 함수
이 두 함수를 보고 다시 앞서 transfer 함수를 떠 올려보면 STM 또 다른 장점을 볼 수 있다. 이 예제에서 withdraw와 deposit 함수는 각각 STM 액션으로 트랜잭션으로 처리할 수 있는 구조를 가지고 있다. 개발자가 transfer 함수처럼 이 두 함수를 하나의 트랜잭션으로 호출하고 싶으면 단순히 이 둘을 do {} 블록에 묶고 atomically만 붙여주면 된다. 이처럼 STM으로 작성된 루틴은 필요에 따라 얼마든지 합성이 가능하다는 장점이 있다.
반대로 이 두 함수를 락으로 구현했다고 생각해보자. withdraw도 락을 잡고 deposit도 락을 잡았다고 하더라도 이 둘을 합성한 transfer는 여전히 문제가 있다. 락을 잡는 순서에 따라서 데드락이 발생할 수도 있고, 별도의 락을 잡아주지 않는 이상 withdraw와 deposit 사이에는 레이스도 존재하기 때문이다. 락 기반 멀티쓰레드 프로그래밍은 작성하기도 어려울 뿐만 아니라 프로그램을 재활용하는 모듈화가 힘들다는 또 다른 숨은 문제점이 있다.
STM 블로킹
지금까지는 주로 락을 대체할 수 있는 STM 액션과 atomically에 대해서만 이야기했다. 여기서 또 하나 특정 조건이 만족될 때까지 블로킹할 수 있는 컨디션 변수의 역할을 해줄 수 있는 무엇인가가 필요하다. 이 역할은 하스켈 STM에서 retry가 맡는다.
limitedWithdraw :: Account -> Int -> STM ()
limitedWithdraw acc amount
= do { bal <- readTVar acc
; if amount > 0 && amount > bal
then retry
else writeTVar acc (bal - amount) }
limitedWithdraw 함수
위 예제는 인출 금액이 잔고보다 많을 경우 잔고가 생길 때까지 대기하는 limitedWithdraw 함수이다. 여기서 주의 깊게 봐야할 부분은 retry이다. retry는 현재 트랜잭션을 취소하고 새로 트랜잭션을 시작하라는 의미이다. 이때 트랜잭션을 즉시 다시 시작할 수도 있겠지만 은행 잔고가 바뀔 가능성이 낮기 때문에 이렇게 폴링(polling)할 경우 굉장히 비효율적인 코드가 된다. 하스켈 STM은 if 문에서 체크한 변수(이 경우 bal)를 검사해 해당 변수가 변경되었을 때 새로 트랜잭션을 시작해준다. retry는 조건이 바뀌면 자동으로 retry가 되는 것을 보장해 주기 때문에 컨디션 변수처럼 영원히 깨어나지 않거나 잘못된 상황에서 깨어나는 버그를 걱정할 필요가 없다.
예제: Buffer
지금까지 알아본 내용을 토대로 간단한 버퍼를 만들어보자.
> module STM where
>
> import Random
> import Control.Monad
> import Control.Concurrent
> import Control.Concurrent.STM
>
> type Buffer a = TVar [a]
>
> newBuffer :: IO (Buffer a)
> newBuffer = newTVarIO []
>
> put :: Buffer a -> a -> STM ()
> put buffer item = do ls <- readTVar buffer
> writeTVar buffer (ls ++ [item])
>
> get :: Buffer a -> STM a
> get buffer = do ls <- readTVar buffer
> case ls of
> [] -> retry
> (item:rest) -> do writeTVar buffer rest
> return item
buffer.lhs STM을 이용한 버퍼 구현
위 코드는 여러 태스크가 동시에 사용할 수 있는 동시 버퍼(concurrent buffer)를 STM을 이용해 구현한 것이다. 여기서 newBuffer를 newTVarIO []로 선언했는데 newTVarIO는 atomically . newTVar과 동일하다. put은 STM 액션으로 버퍼의 끝에 원소를 하나 더 한다. ++는 리스트 두 개를 더해서 새로운 리스트를 만드는 함수이다. 여기서 buffer는 크기 제한이 없는 큐이므로 put은 블로킹하지 않는다.
get의 경우 리스트에서 첫 번째 원소를 빼고 나머지를 다시 저장한다. 이 때 buffer가 비어있을 경우가 있으므로 buffer가 비어있으면 retry한다. retry는 ls <- readTVar buffer의 ls에 의존적이므로 다른 태스크가 buffer에 새로운 원소를 put하는 순간에 깨어나서 다시 트랜잭션을 시도하게 된다.
맺음말
정리하자면 STM의 가장 큰 장점은 기존 락/컨디션 변수 기반의 멀티쓰레드 프로그래밍보다 훨씬 프로그래밍 하기가 용이하다는 데 있다. 또한 STM은 근본적으로 데드락이나 컨디션 변수의 잘못된 깨어남 등의 가능성을 차단해 주고, 코어가 늘어났을 때 규모가변성을 어느 정도 보장해준다.
STM은 아직 많은 개발자들이 사용하는 일반적인 방법은 아니다. 하지만 오랜 시간 여러 연구자들이 검증해온 아이디어이고 현재 기존 프로그래밍 언어에 접목하려는 시도가 활발히 이루어지고 있다. 특히 하스켈 커뮤니티에서 가장 먼저 그 시도가 이루어졌고, 이 글 역시 하스켈과 STM에 깊은 기여를 한 마이크로소프트 리서치의 사이먼 페이튼 존스(Simon Peyton Jones) 글과 강연에서 많은 도움을 받았다.
앞으로 다가올 멀티코어 시대를 맞을 준비는 STM으로 시작해보자.
참고문헌
[1] Beautify concurrency, Simon Peyton Jones
http://research.microsoft.com/~simonpj/papers/stm/beautiful.pdf
[2] Lock -Free Data Structures using STMs in Haskell, FLOPS'06
http://research.microsoft.com/Users/simonpj/papers/stm/lock-free-flops06.pdf
[3] Composable memory transactions, PPOPP'05
http://research.microsoft.com/Users/simonpj/papers/stm/stm.pdf
[4] stm-2.1.1.0: Software Transactional Memory
http://www.haskell.org/ghc/docs/latest/html/libraries/stm/Control-Concurrent-STM.html
- Filed under : Concurrency
